Day 271: DI..why?! – Awkward lighting

What do you do when you want to install this, but the electrical box is 8 inches to the right? Well let’s go over that!
Well since I anticipate a lot more DIY posts, I’ve created a new category for them! I’m calling it DI…why?! because every time I try to fix something, I find something else that was wrong with the way they built the home. To kick this off, let’s talk about the curious case of the cockeyed casing. Or without the alliteration, the stupid builders put the electrical junction off center for no apparent reason and we’re going to fix that.
First a word of caution and a bit of information on electrical code. First always turn the power off to the circuit you are working with, yes turning off a lightswitch means there is no power at the line, but it never hurts to be overly cautious when you’re working with electricity. You may accidentally bump the switch for example, or worse someone in the house may bump it while you are working with the line… that would be bad.
Second, if you find yourself in the same situation I was in it may be tempting to try to run a wire behind the drywall and have the wire exit at the center spot. They you may be so inclined to just plaster over the electrical junction and forget about it. DO NOT DO THIS. That is a fire hazard, it is not up to code, and despite the cringeworthy youtube video I found of someone doing just this, it is wrong and you can cause serious problems.
Instead we will remove the box from it’s secured location, reposition it where we want it, then seal the holes we made and paint. Sounds simple? Well for the most part it is! Yes, it’s a little bit of work, but better to do it the right way than to burn your home down because you wanted to save a few extra hours of work. Now with that ample caution let’s go ahead and dive right in.
First I opened the wall up using a drywall saw. They are cheap and do the job really well, I mean it’s literally called a drywall saw. Get one before you start doing the job and you will not regret it. It makes the work so much easier. You’ll want to cut a hole big enough for your box, but you want to keep it as small as possible in my opinion. This will make less work for you in the long run, but you can open it up as much as you need.
Unfortunately I found that I did not have a whole lot of photos of the process I will be talking about, but I will share the few I took and fill in the blanks for you. If I had to rate this on a scale where 1 is the most simple job someone doing home renovation could do and where 10 would be the most complex job a home renovator could do I would rate this a solid 3. It’s simple enough that if you follow along even someone new could do it relatively well and it is very difficult to screw up. Here is the first shot we can talk about, you can see that I opened the wall up to the left of the box because that is where I wanted to place it. I needed to find a stud in the wall (the wood) to mount it to, so I cut the hole large enough to see the two studs above the sink where this fixture is going. Notice it isn’t much bigger than the size of the box, hint, hint!

Where is the second stud you may be asking? See the end of the hole on the left, right next to that black insulation (which is covering the second pipe) is the second stud. You never want to open a wall more than you need, so I stopped there. Then I needed to determine how the box was attached, sometimes they are attached in odd ways, this one was fairly standard, two nails on the top and bottom of the box you can see the ears for the nails in the photo, but I’ve labeled a few things for you to make this easier in the image below.

Now that I knew what was going on I could move the box to the other side of the stud. There are a few caveats to this, first you need to make sure your wires are long enough to do this, you cannot splice extra wire inside the wall without a junction box. It will not be up to code, do not do it, you can cause a fire so don’t do it! Second there is a stud and either the hot or cold water line, I wasn’t sure which and it didn’t matter, the point was it was in the the way and I couldn’t help that. Let’s take this in order.
First I removed my electrical box. Here’s where photos are sparse and I apologize, I’ll be better in the future. That took a bit of work, but I wanted the hole around the box as small as possible so I did what I could using a flathead screwdriver to start backing out the nail, once I got it a little out it was quite easy to pull off by hand. Your mileage may vary on that, but if you are careful you can do it too. Second I needed to see if there was slack in the wire. I had a little, but not enough, I’ll explain what I did and how I did in a moment.
Next I was ready to move the box, first I needed to route the electrical to the other side of the stud, to do this, I drilled a small hole in the center of the stud. You’ll want to keep it small and you’ll want to make sure it is centered, especially if this is a load bearing wall. They sell reinforcing plates you can use if your wall is load bearing and you need to reinforce the stud or if you are not sure if it is load bearing and want to reinforce the stud, you can read more than I could cover in this post about the do’s and don’t to drilling into a stud here.
So my wire made it to the other side, but the box was just going to float since I could not attach it to the pipe… right? I cut a piece of 2×4 and ran it from one stud to the next and screwed it into place. Again, no photo… oops. However I can draw a lovely guide so you can see what I did. The pipe as you may notice was close to the drywall, so I had plenty of space to run this behind the pipe and screw it into place.

You can move the fiberglass insulation around to fill in the hole left when you remove the electrical junction box. Do you need to do this? No, I suppose not, but it’s a good idea and you’re already in the wall so you might as well do it right. I had a difficult time securing the far end of the board since I couldn’t get to the back side of the stud, so I did my best and angled a few screws into it and the stud, be careful not to hit the pipe! The side close to where the box originally was (right) was easy since I had access to the other side of the stud, I could screw directly into the board I was adding without any fuss and again, mind the pipe.
Next you’ll run the electrical into the junction box, I do this before securing the box and if you try to feed the wires into the box you’ll see why, it isn’t the easiest thing in the world to do. Next test fit the box, you need it to be flush with the drywall or at least very close. To test this, place it up against the wood backer you just secured and use a ruler or some sort of flat edge long enough to touch the top and bottom of the drywall. If it doesn’t come forward enough, you can use other thin scrap wood to add a spacer.
Once you have it attached you can screw it into place. Most electrical boxes have several alternative ways to mount the box, mine had holes in the back of the box and those are what I used since my board was in the back of the box and not the side like the original way it was mounted. Once you’ve got your box centered (or placed where you want at least) secure it into place. You can now reattach the drywall you removed.
To do this step (again no real photos… I know!) you can grab a 2×4 and screw it down to the wood backer This should place it in line with the back of the other drywall, if not you’ll need to use a spacer in between. Do this for both sides of the hole you just made. I’ve modified the above drawing to show you what I am talking about.
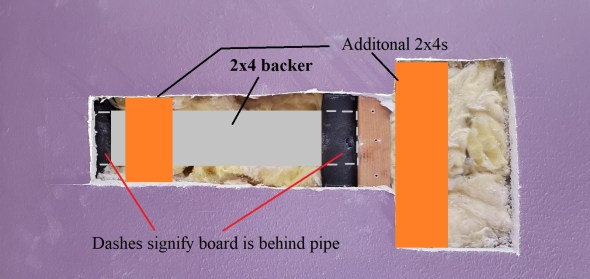
These provide support for the drywall you’ll be reattaching. There are a lot of different methods you can use to do this step, I like using 2×4 to provide the backing. If the drywall can move, it will cause cracks so this to me seems to be the best way to prevent that from happening. You can attach enough to cover most of the back, but this should be the minimum. Now you can screw your drywall in using a few short screws and mount it to the backing. I just reused the drywall I had and cut the hole for the new location of the junction, then used that piece to fill the hole left from the original location of the box.
Screw everything down and now there are gaps, at this point you have a few options I like to use a backing tape. There are two main kinds you can use, paper tape and fiberglass mesh tape. I prefer the fiberglass version, but everyone has a preference and I don’t think it matters too much. Here is what the fiberglass tape looks like.

Now that you’ve taped over the gaps with a little extra on your drywall you should be ready for spackle. You will go well over your patch because you want to blend it seamlessly. There is a thickness to the drywall tape and the boards may not be perfectly flush to the wall so we will build up a thin coat of spackle then for our top coat we will use some plaster. There is a difference! Spackle is to fill in holes, it is thicker than plaster, but drys faster and does not shrink. You can use plaster if you want, they are both derived from the same material (gypsum), but it takes forever to dry and there is going to be shrinkage so you’ll have to go over it with multiple coats. I finally (yep) have a photo to show for this step!

This was my first step to filling everything and making sure it was all level, The next step, which I do not have a photo of is making it all nice and blended. I went over my project with 2 coats of spackle and 1 top coat of plaster to make sure it was all leveled out. Then we sand it all down smooth and nicely blended to the wall, the problem is the walls around this patch are not smooth! Next, I taped over the electrical box opening and sprayed on some wall texture. Matching wall texture is an art, but as long as you are close no one will notice… except for you, you will ALWAYS notice. Do you really need to tape over the electrical box for this step, no. I do it because I like keeping everything clean, but it isn’t a requirement. Here’s a photo of the texture spray I use, my walls have a sort of runny orange peel look that I’ve never actually seen before, so I do my best to match, but again no matter how close you get you’ll always know it isn’t original.

Once I was done, I painted over my patch job. Here’s a photo of the still wet paint that I applied. You can notice how far out I went from the patch job with the plaster, you’ll want to do the same, trust me it will make for a smoother transition that will look better than if you try to keep the patch small.

So here is where I talk about my issue with the wire. I barely had enough to make it to the box, so I had the wire inside the junction box, it just wasn’t long enough to easily attach it to the fixture. Luckily inside a junction box we can add wire, so I did just that, attached extra wire to the short one. There are going to be a minimum of three wires in your box, a line (this is where the power comes from) a load (that would be the other line to the fixture and completes the circuit) and a ground (this will always be a bare wire), in my case all the wires were long enough except for the load wire, so I spliced on a bit of extra romex wire (that’s the name of the wire run throughout your house and it is solid core copper wire for a reason) and was ready to attach my light fixture. Photo time… finally!

This was the first time I turned on the fixture. Yay it works and it is centered to my sink! Woo!! Okay, here is another shot of it off. This one shows the wall better.
Not the straightest photo I’ll grant you, but you’ll notice the wall behind looks nice and solid. You cannot tell where the original wall stops and my patch starts, which is the point! That’s basically all you need to know! Thankfully, in most cases you’ll have enough wire and won’t need to add a splice inside the junction box. I felt weird doing it, but it made it easier to attach the fixture and it’s within code, so there is no reason why I couldn’t do it. At the end of the day it was a few days worth of work, but most of that time was me walking away from it and letting everything dry before I did the next step.
What’s really frustrating, I’ve run into this issue for every single bathroom in my home (okay I make it sound like I have a lot of bathrooms, but there are 3, 2 full bath and 1 half bath, this was the half bath). The weird one was the non-master bath, there was no reason for it not to be centered even if they were being lazy, yet it was still off by a good 6 inches, so it was very noticeable!
Tomorrow I can showcase a few other random patches I’ve had to make around the house. I took some during photos, but I never planned to showcase my work like this, so from here forward I’ll try to get better during photos to make it easier to follow along! Hopefully you’ve learned something and I didn’t confuse you too much. Later we’re going to get into some light switch replacement soon, so that will be fun.



That’s a better patch job than I could’ve done! 😁
LikeLiked by 1 person
May 16, 2020 at 1:00 pm
Thanks! I don’t think I’m that good at it, but the secret is a lot of patience and a little bit of practice.
LikeLiked by 1 person
May 16, 2020 at 4:11 pm