Day 44: Functions of One Random Variable Example Part 1
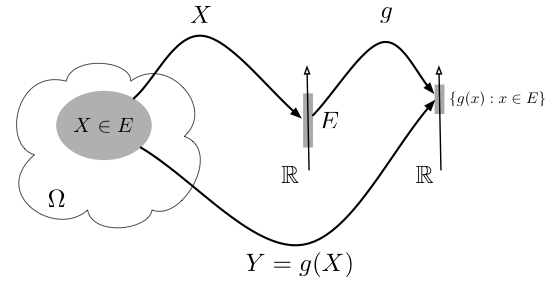
Really, this is all we are doing, but let’s make some sense of it.
Well maybe yesterday was confusing, maybe it wasn’t. In any case, today should clarify some things for you if you are confused and should make things more clear if you are not. Today we are going to go over a quick example of what a function involving one random variable looks like. Now you may notice I keep saying one, that’s because you can technically have as many variables as you want, but since this is fairy complex stuff, let’s just stick with the one for now.*
The past couple of days have been a little… complex. Fear not, today I think we are going to clear up some confusing parts. If you haven’t you should read the last post about functions of a single random variable. Fair warning, this will make much more sense if you review that (even if it is a little confusing).
There are a few ways we can go about doing this, but let’s look at a somewhat easy example to start. Let’s use our uniform distribution for this one. Let’s say X is a Uniform(0,1) random variable. In this case we already know everything we need to know about X because we know the formula for the uniform distribution. However, this is a function of a random variable, so now let’s say we want some function g(X) in that case we would have:
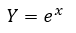
For this example let’s find the CDF and pdf of this function. Because Y = g(X) is a function of X, we know Y is also a random variable and we can solve this like we would solve any other random variable examples. First let’s take note that we already know where X lives (we know its pdf and CDF), so we know
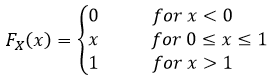
So we know the range of our X, but it would be smart to think about the range of our Y function before we try to determine the distribution. Now we know that e to the power of anything positive will be an increasing function based on x. We also know that the range R of x is [0,1]. That just means we know that the interesting bits live in the interval of zero and one, everything else is either zero or one depending on the value of x (as we saw above). From this we know what the range is for our Y variable since we can just plug in the maximums from X, which is going to be between 0 and e to the power of zero is going to be one. We also know that e to the power of 1 is just e, so we can already say that the range of our new function Y is going to be [1,e]. This means
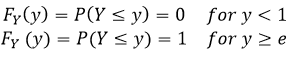
So far so good, we already know the limits of our function just based on what we know about X. Now we can try to find the middle bit, the part where the interesting things happen. Let’s do that set by step and we can explain why we did what we did at the end
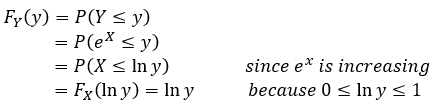
Intuitively this should make sense, we just related our output in terms of our X, remember that
and if we take the natural log of both sides we end up with ln(y) = X. Which we had to find the new range in our Y space (that bit we did at the beginning when we find out where our function is equal to zero and when it is equal to one. Furthermore we can double check that this makes sense because if we take the limits of our function and plug it into our new derived function Y we see that ln(1) = 0 and ln(e) = 1 and we cannot have negative probability, we know that our CDF needs to be increasing (which it does) and cannot pass 1, which again we know it fits since we just looked at the limits. We can sum this up like we did for X and write it like this
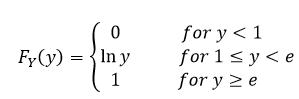
Okay so if you’re still with me to this point, we have a continuous function, yay. This is a good thing because we only have the CDF, we need to determine our pdf and we know that to find our CDF from a pdf we integrate, so to go backwards, we take the derivative. This is just some basic calculus (which by now I hope if you’ve been following along you’ve brushed up on… right?). Thankfully taking the derivative of the natural log is pretty straight forward even if you’re new to calculus.
Side note: I say this a lot, we want to be lazy and I mean that literally. We don’t want to have to do a lot of work to find a solution to a problem. Why? Because that increases the chances we will make an error and we don’t want that. Plus, we’re lazy so why do all that work when you don’t need to. If you ever find yourself trying to solve a math problem (specifically one for a class) step back and see if you can be lazy, chances are it is the right way to do it.
Okay so now from that aside, we take the derivative of our CDF and find our pdf. When we do that, we end up with
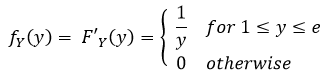
Okay, TECHNICALLY we cannot differentiate at 1 or e, but we don’t need to worry about this since this is a continuous random variable and changing the pdf at a finite number of points does not change probabilities (remember the probability that something will occur at exactly a single point is ZERO! So we can include these here for completeness and because these are the limits of the CDF so changing them would be confusing and worse, pointless (no pun intended… okay a little intended).
Well that was fun! Okay so a few things left to cover and then we will have caught up to where I am and then we can (hopefully) do more examples of this stuff and some much needed review (well for me, I’m sure you’ve got this down). I sincerely hope that the example not only clears this up some, but helps give you the formula we will be using to solve these problems (find the limits, then the middle bit from those limits, then take the derivative to find the pdf). We’ll go over some more examples though, don’t worry and we have so many fun things to talk about going forward (can we say functions of multiple variables?!).
Until next time, don’t stop learning!
*My dear readers, please remember that I make no claim to the accuracy of this information; some of it might be wrong. I’m learning, which is why I’m writing these posts and if you’re reading this then I am assuming you are trying to learn too. My plea to you is this, if you see something that is not correct, or if you want to expand on something, do it. Let’s learn together!!



But enough about us, what about you?