Day 42: Conditional Probability

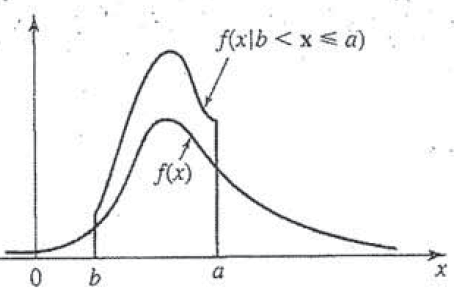
How does this not exist on the internet?! This is directly from my book, so it looks a little… well loved.
Up to now we’ve been dealing with single variable pdf and the corresponding CDF. We said that these probabilities relied on the fact that our variable of interest was independent. However, what if we knew some property that impacted our probability? Today we are talking conditional probability and that is the question we will be answering. It’s going to be a long, long post so plan accordingly.*
Day 41: Connecting the Concepts


Maybe we shouldn’t phrase it this way, since there is still quite a few days left of 365DoA, but you made it to the end! No, not THE end, but if you’ve been following along the past few posts we’ve introduced several seemingly disparate concepts and said, “don’t worry they are related,” without telling you how. Well today, like a magician showing you how to pull a rabbit from a hat, let’s connect the dots and explain why we introduced all those concepts!*
Day 40: The Normal Approximation (Poisson)

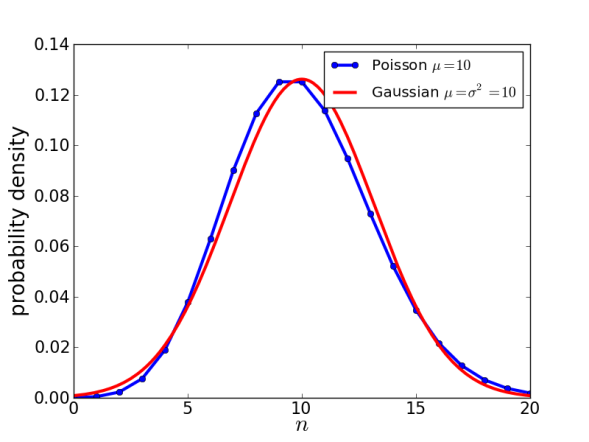
Poisson’s return!
Day 39: The Normal Approximation (De Moivre-Laplace)

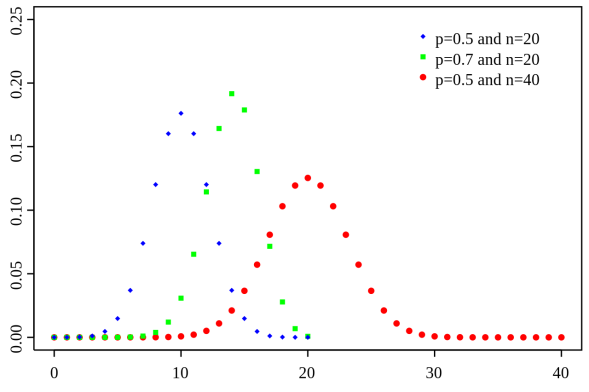
The binomial distribution, don’t worry we’ll get into it.
Day 38: The Poisson Distribution

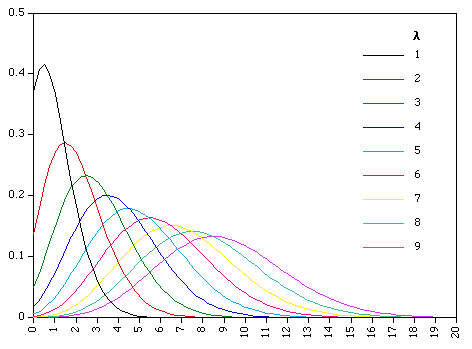
The Poisson distribution changes shape as λ changes
Day 37: Bayes’ Theorem

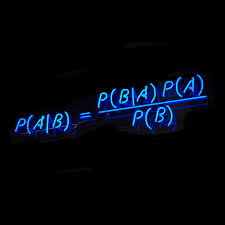
We’re talking Bayes for days.
Day 36: The uniform pdf

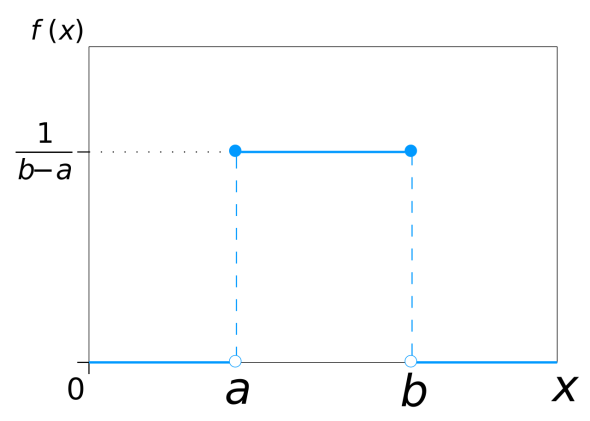
The uniform distribution, a very simple looking distribution indeed.
Day 35: Example of the Gaussian pdf


The gaussian (or normal) distribution demonstrated by plinko.
Day 34: Example of the Laplace pdf


The Laplace pdf (left) and the associated Laplace CDF (right). Remember the CDF is just the area under the curve of the pdf.
Day 33: Example of the Exponential pdf

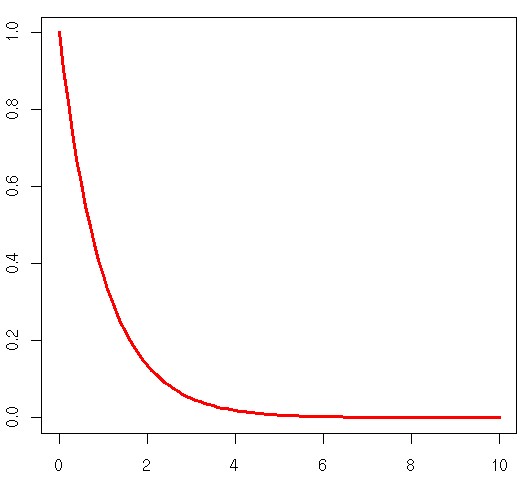
For those who need a refresher, this is a plot of the exponential pdf we are working with today.
Over the past couple of days, I’ve been talking about several different types of pdf and the associated C.D.F. Hopefully, we have a clear understanding of each of those concepts, for those of you scratching your head, I would recommend you start here at this other post. Otherwise, let’s (finally) look at a real life example using the exponential pdf!*
Day 32: The Laplace pdf

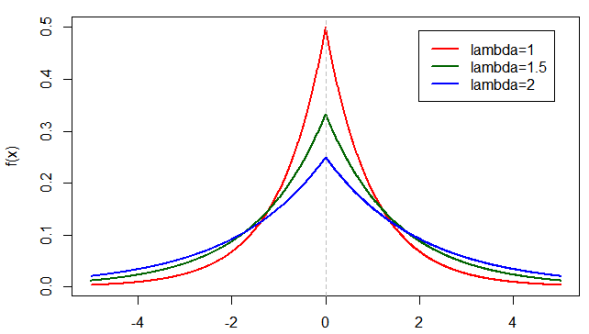
The laplace p.d.f with a θ = 0.
Well here we are again… maybe unless you’re new, in which case welcome. If you are just joining us we are talking p.d.f. no not the file format, the probability density function version. If you’re new, you may want to start back here(ish) If not, then let’s talk the strangely similar laplace distribution.*
Day 31: The Exponential pdf

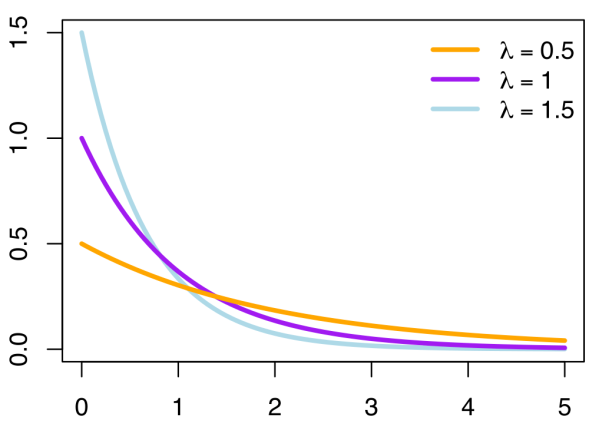
Today we are talking this guy! The exponential p.d.f and its C.D.F.
Well, it has been a week, don’t even get me started. But if you’re here you don’t want to hear me complain about my week, that isn’t why we come together! Well today let’s do a bit of a dive into the exponential p.d.f. I hope you’ve brushed up, because this is going to get interesting.*
Day 30: Confidence Interval

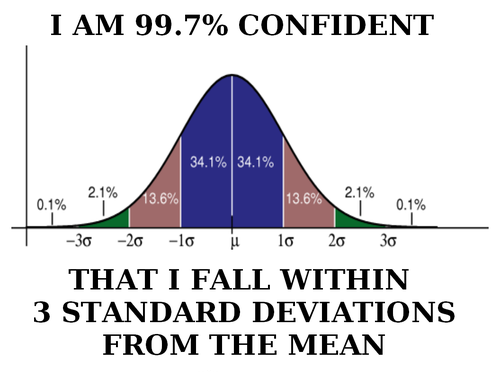
Yep, we’re talking confidence!
Day 30 already! Where does the time go? It feels like we just started this whole project and it probably wouldn’t be a good idea to look at the remaining time to completion, so let’s not and just enjoy the nice round 30. We will get back to our p.d.f another day, but today is going to be short. That’s what I usually say before typing out 10 pages worth of information so to avoid that, let’s touch on something important, but something I can do briefly. Today we’re talking about confidence intervals*
Day 29: Probability density functions, Part 3

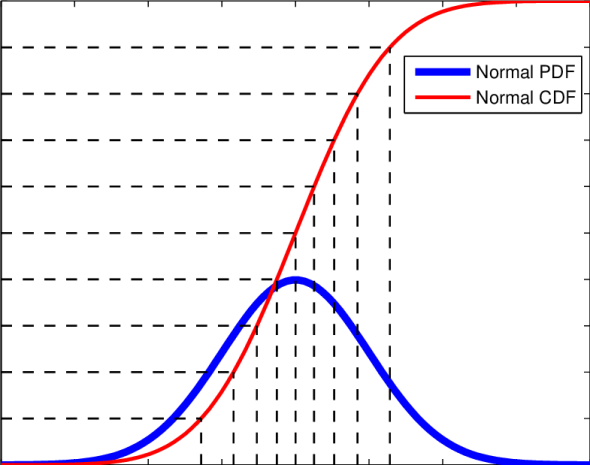
Don’t be scared, we’re going to tackle this guy today!
Well, apparently you guys really appreciated my probability density function posts. It’s good to see people interested in something a little less well-known (at least to me). So for those of you just joining us, you’ll want to start at part 1 here. For those of you who are keeping up with the posts, let’s review and then look at specific functions. Namely let’s start by going back to our gaussian distribution function and talk about what’s going on with that whole mess. It will be fun, so let’s do it!*
Day 28: Cumulative Distribution Functions

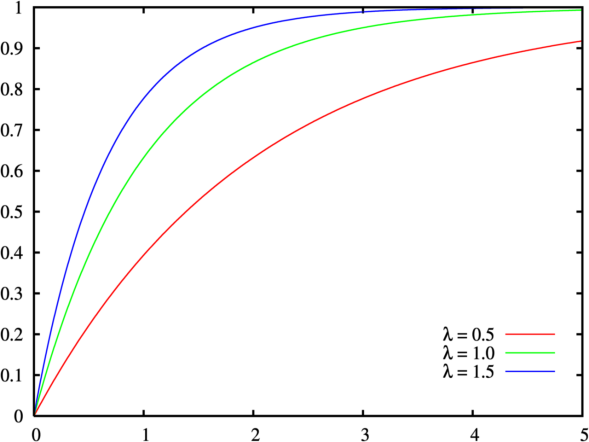
An example C.D.F. of an exponential distribution
Today we were going to do another deep dive into the p.d.f and C.D.F. relationship. Specifically today we were going to talk about specific p.d.f. functions and why we use them, however… I am not doing so hot today, so instead we are going to back track just a bit and talk about what how a C.D.F. differs from our p.d.f. even though we kind of covered it, it would be nice to be clear and I can do this in a (fairly) short post for the day. So that said, let’s get started and we will pick up our p.d.f. discussion next time (maybe).*
Day 27: Probability density functions, Part 2

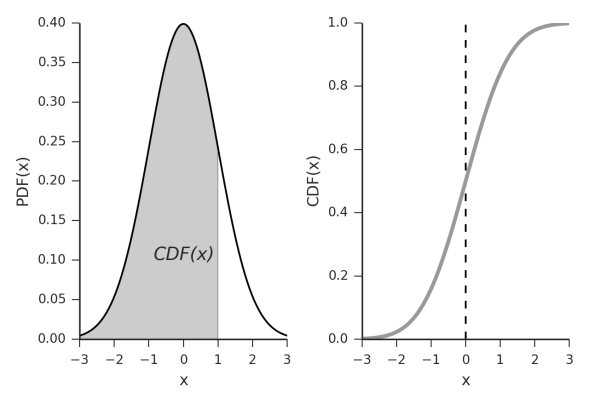
Today we are looking at our p.d.f. (yes this image has p.d.f. written as PDF, please don’t be confused!) and our C.D.F.’s let’s do this!
Oh hi didn’t see you there. Today is part 2 of the probability density functions notes (posts?), whatever we are calling these. You can read part 1 here as you should probably be familiar with the (super confusing) notation we use to describe our p.d.f. and our C.D.F. now that we’ve given that lovely disclaimer, let’s look once again at probability density functions!*
Day 26: Probability density functions, Part 1


Dashing dreams one comic at a time, via Saturday Morning Breakfast Cereal
We are well on our way to wrapping up week 4, what a ride it’s been! It’s been a long day for me, so today might be short. However, I really, really, really want to break into probability density functions. This topic is going to be a bit more advanced than some of the things we’ve covered (IE more writing) so it will most definitely be broken up. Let’s look at why and discover the wonderful weirdness of probability density functions!*
Day 25: The p-value


It’s true!
Now it seems like we are getting somewhere. Last post we covered z-score and you can read that if you haven’t already, it might be good to familiarize yourself with it since today we are going to talk p-value and the difference between z-score and p-value. That said, let’s dive in and look at the value in the p-value.*
Day 24: The z-score


So if you recall from last post… well I’m not linking to it. It was hellishly personal and frankly I’m still attempting to recover from it. We’re going to take it light this time and we can do a deep dive into something in another post. For that reason, let’s talk about z-score and what exactly it is, I mean we used it in this post and never defined it formally, so let’s do that. Let’s talk z-score!*
Day 23: I was lucky…


This was home, for a while anyway.
Okay, so not every post has to be strictly academic. If my twitter feed is any indication yesterday was world suicide prevention day. So with a heavy heart I have not one, but two very personal stories regarding suicide. Obviously this is a content warning for those wanting to go further, we will be dealing with suicide, death, and suicidal ideation.
Day 22: Parametric vs. NonParametric Statistics


Technically we could call this parametric statistics part 2. However, since we are covering nonparametric statistics and more importantly the difference between parametric and nonparametric statistics, it would seem that this title makes more sense. As usual with a continuation, you probably want to start at the beginning where we define parametric statistics. Ready to get started?*
Day 21: Defining Parametric Statistics

It’s halloween time, we are talking about normally distributed data, so this fits, and I don’t want to hear otherwise!
Well my lovely readers, we’ve made it to the three week mark, 5.7% of the way through! Okay maybe that doesn’t seem like a big deal written like that, but hey it’s progress. So last post we had our independence day, or rather defined what it meant to have independent events vs. dependent events. We also said it was an important assumption in parametric statistics that our events are independent, but then we realized we never defined what parametric statistics even is, oops. So let’s stop dragging our feet and talk parametric statistics!*
Day 20: Independent Events


By: xkcd
Because we introduced the central limit theorem last post, it’s time to introduce another important concept. The idea of independent events, while this may seem intuitive, it is one of the assumptions we make in parametric statistics, another concept we will define, but for now let’s jump into independence.*
Day 19: The Central Limit theorem


Well here we are again, if you recall from our last post, we talked Bonferroni Correction. You may also recall that when the post concluded, there was no real topic for today. Well after some ruminating, before we jump into more statistics, we should talk about the central limit theorem. So let’s do a quick dive into what that is and why you should know it!*
Day 18: The Bonferroni Correction


By now we are masters of statistics… right? Okay, not really, but we are getting there. So far we’ve covered two types of errors, type 1 which you can read about here, and type 2 which you can read about here. Armed with this new knowledge we can break into a way to correct for type 1 errors that come about from multiple comparisons. Sound confusing? Well, not for long, let’s break it down and talk Bonferroni.*
Day 17: Type 2 errors


Last post we did a quick bit on type 1 errors. As with anything, there is more than one way to make an error. Today we are talking type 2 errors! They are related in the sense and we’ll go over what that means and compare the two right… now!*
Day 16: Type 1 errors


We did it, we cracked the coin conundrum! We managed the money mystery! We checked the change charade! We … well you get the idea. Last post we (finally) determined if our coin was bias or not. Don’t worry, I won’t spoil it for you if you haven’t read it yet. I actually enjoyed working through a completely made up problem, so if you haven’t read it, you really should. Today we’re going to talk dogs, you’ll see what I mean, so let’s dive in.*
Day 15: Significance, Part 3

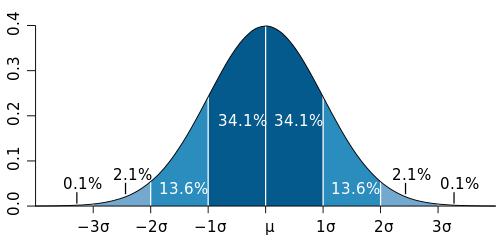
Where does our observation fall on the probability density function?
It looks like we’ve arrived at part 3 of what is now officially a trilogy of posts on statistical significance. There is so much more to say I don’t want to quite call this the conclusion. Instead, let’s give a quick review of where we left off and we can get back to determining if an observed value is significant.*
Day 14: Significance, Part 2


Z-score bar graph that I made just for all of you using some data I had laying around. If you’re new to statistics it may not make sense, but rest assured we will make sense of it all!
Well here we are two weeks into 365DoA, I was excited until I realized that puts us at 3.8356% of the way done. So if you remember from last post we’ve started our significance talk, as in what does it mean to have a value that is significant, what does that mean exactly, and how to do we find out? Today is the day I finally break, we’re going to have to do some math. Despite my best efforts I don’t think we can finish the significance discussion without it and still manage to make sense. With that, let’s just dive in.*
Day 13: Significance, Part 1

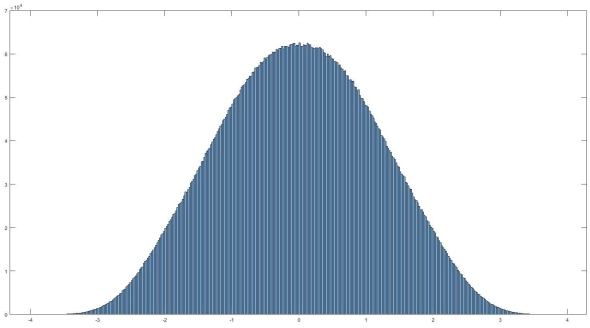
Histogram of normally distributed data. It looks very… nomal. No it really is normally distributed, read on to find out what that means and how we can use it.
If you’ve read my last post I hinted that today we would discuss filtering. Instead I think I want to take this a different direction. That isn’t to say we won’t go over filtering, we most definitely will. Today I want to cover something else though, significance. So you’ve recorded your signal, took an ensemble average, and now how do we tell if it actually means something, or if you are looking at an artificial or arbitrary separation in your data (IE two separate conditions lead to no difference in your data). Let’s look at significance.*


