Time for an upgrade


Okay, it’s not the best of times, but it’s not the worst of times either. Wait, I didn’t do that intentionally, but it works. Maybe I should’ve titled the post a tale of two monitors! It’s back to crunch time though meaning late nights from here to the end of the month, well at least until the end of the DARPA deadline. It’s going to be a challenge, but I’ve got a new toy to help me make it through. Well a new monitor to be exact. Sometimes you just have to buy yourself something nice.
(more…)More coding adventures


It’s another day and another chance to make progress with data processing. Since it’s been a busy few weeks since hospital-PI has returned to the lab, I haven’t had a ton of time to work on the dataset that we collected, the first of hopefully many. However, the initial analysis is done, so it’s time to move forward and start thinking about what comes next. That is, how can we refine what we’ve done? There’s a lot of steps I can take, but I think today we’ll sum it up and narrow it down to the steps I’m most excited about.
(more…)Race to the deadline


What is it about self-imposed deadlines that feel more important than the ones you hardly have control over? Maybe it’s because I’m competitive or maybe it’s just that I hate failing at something that I set for myself, but whatever the reason tomorrow is my latest deadline and I’m so close to finishing I can taste it. So today I’m hoping to finish my coding work so I can process some more of the “big idea” dataset I collected several weeks ago.
(more…)The first flush


With fancy computer equipment comes annoying computer maintenance. Today has been a challenge! Thankfully finished, mostly. It’s been roughly six months since I took the plunge and built my own custom watercooling loop for my computer. Since today is the first flush, I figure I can tell the story and talk about how it went. Spoiler, it went both better and worse than I expected.
(more…)Technology issues…


I’ve quickly come to regret purchasing my new(ish) fancy laptop. I get complements on it because it looks impressive and if it worked correctly it would be very impressive. The problem is that it has been causing me headaches since I bought it. Technically this is the second one, the first one was replaced and the second had the same exact issues. So instead of exchanging it again and going through that whole mess, I decided to crack it open and do the fixing myself.
(more…)A beginners guide to watercooling, from a beginner.

I have built a lot of computers over the years. It’s actually not that hard to do since most things are labeled and use different types of connectors so it’s hard to screw it up unless you’re not paying attention. Up until recently I’ve never watercooled a PC, at least not in the build it myself sense. The internet is full of how-to guides to help you do this, but most of them are from people who do these types of builds regularly. I find that they skip over some of the basic things that you may need to know because they’ve forgotten that it’s not common knowledge. Since I’ve successfully finished my first build and don’t like hoarding knowledge, I want to share how to do it, for beginners, by a beginner.
(more…)PC build part eight, closing the loop


As promised this is the grand finale to the custom water cooling hard tube build saga. As in, the computer is back up and running… finally. It’s been a journey, but I’m hopeful that the latest mods will keep me from having any more problems that I need to stop my work and fix. I mean modding your computer for fun is one thing, needing to do it is a whole other thing. Still, I’m thankful for the little pause and I got to make a few needed changes/upgrades while the computer was down so it isn’t all that terrible.
(more…)PC build part seven, the tale of the leaky loop


Well I’ve done it… mostly. The loop is finally complete and I’ve pressure test it. There were of course some technical difficulties, which I resolved, but I also caused because I’m an idiot. I wasn’t planning on making another computer post until I had the thing turned on and finished, but today I want to tell the story of how a $20 USD part saved my computer.
(more…)PC build part six, now with more bends!


Yep, still working on the hard tube bends. It’s a lot… harder than it looks! Pun fully intended. Today I have good news and bad news. The bad news is there’s still some work to be done before I get to pressure test and finally finish this build. The good news is there’s only one bend I need to make and one or two I would like to redo if I have enough tubing for it.
(more…)PC build part five, the first bends


We’re getting bendy! After all the work I had to do yesterday I didn’t think there would be time to bend tubing yesterday, but I was determined to get started and I did. The good news, some of it’s done. The bad news, bending tube isn’t easy. There was a lot of trial and error, even more waste, and even now it’s not perfect *sad face* … but it’s almost time to wrap this project up!
(more…)PC build part four, electrical fire edition!


Okay, okay clickbait headline, I admit it. If you’re here for a real electrical fire you’re out of luck. Thankfully I haven’t had an electrical fire… yet, I haven’t turned the computer on since I’ve started this project. However, a few things happened yesterday so I need to figure out my cable management before I get too much further. It’s something I’ve been ignoring and I’m finally sharing some of the mess that I’ve (somewhat purposefully) been hiding.
(more…)Part three, extreme PC modding!


It’s no secret, it’s been a hell of a week for me. To help distract me (unsuccessfully) I decided to do some of the major mods to the PC that needed to happen in order to get everything the way I want it for the final assembly. I’m hoping tomorrow will be that day, but there are still (STILL) parts I’m waiting on, so it may be a photo finish. If not, well I can always finish is during the week or next weekend (probably).
(more…)Day two, the computer teardown


Well it’s day two of the big computer watercooling loop install and I’m already running into several problems. Some of them can be fixed quickly, while others… let’s just say I needed to get different parts so I’m in the process of doing that. As promised, there are tons of photos and explanations of everything I’ve done so far and why this is turning into a headache. Sometimes doing a custom job means getting extra custom.
(more…)Day one of the computer rebuild


Well today’s the day I crack open the computer case and get to work on fixing my desktop computer. Since I have not popped anything open yet, I want to talk a bit more about the plan going in, how I am going to do things, why you should do it too if that kind of thing sounds fun to you, and why I selected some of the things I did.
(more…)The computer rebuild plan


Okay after yesterday’s news that my computer is once again limping along I spent the day trying to figure out what to do. After spending a ludicrous amount of time researching and finding the parts I want to replace the clogged garbage I’m currently dealing with I think I have it all figured out, but it’s not going to be an easy (or cheap) fix. The good news is this is going to be the ultimate solution, the one that will (hopefully) be the last fix until either something breaks, I rebuild the computer completely, or I graduate.
(more…)Technical difficulties


Well if it isn’t the consequences of my own actions. Or maybe not, maybe I’m just unlucky. I am once again having desktop computer troubles. It’s the return of the heat issue, thankfully this time I caught it somewhat early (I think). Since this seems to be a reoccurring issue I think we’ll try to fix it with a slightly more permanent solution. The problem? The cost, this couldn’t have happened at a worse time, but not all is lost, at least not yet.
(more…)Intro to MATLAB – Part 5


Well we’re doing it. We’re adding to the MATLAB course I taught. Today we’re going to dive into functions, more importantly why you may want to write your own function, when you probably don’t need to, and how to tell the difference. This of course was inspired by the stuff I had to do the other day and when I realized I should just stuff everything into a function, life became a lot less complicated. Don’t worry, functions are your friends!
(more…)I’m teaching solid modeling, again.


Well I got a surprise email from my main-PI yesterday reminding me that I was teaching two classes this week. I knew it was coming, the surprise was that the summer courses are still going on, I haven’t gotten a single email about them since I taught my intro to MATLAB class. Normally when I teach I put all the information out there on the web for all of you to use it how you see fit. This class isn’t going to be that way, but there’s a good reason for it.
(more…)Intro to MATLAB – Part 4


We made it! This is the last post (for now anyway) in my four part Intro to MATLAB series. I reserve the right to go back and write more on the topic, but at the moment this is the end. If you’re just finding this and want to read the other posts in the series, I’ve made a super helpful Intro to MATLAB category where they are listed. Today we’re going to take a dive into editing code, finding ways to make your life easier, and just some bits of magic I’ve learned over the years that makes my life so much easier now. Let’s goooooo!
(more…)Intro to MATLAB – Part 3


To debug or not to debug. Just kidding you’re always going to need to debug. My class has officially ended, so this weekend we’re posting the last two parts to the four part Intro to MATLAB series. This lecture I taught my class how to use the debugger in MATLAB to solve any sort of problem they may run into and how to make sense of any issues they had. Unfortunately this means there is no code associated with this class, but we can still go into detail. The best part about being able to debug is that it makes you look like a coding god, so it’s a skill worth learning.
(more…)Intro to MATLAB – Part 1

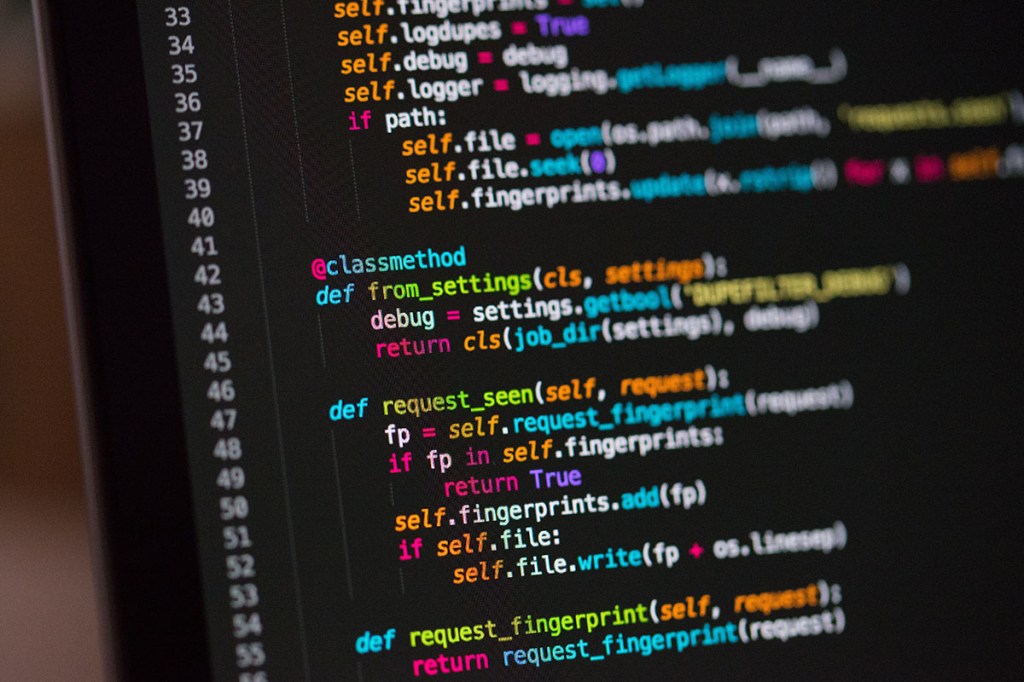
Per my usual routine, I’m teaching a class and instead of hording the knowledge I’m putting it here for all of you to use! I’m even going to attach the example code I wrote, which has enough comments to fill a small book, to help everyone just starting out. As I explained to my students, this is an intro to MATLAB course so my focus is on showing how things are done in MATLAB and less on how to problem solve using MATLAB. Although the last two lectures have not been created yet so they may focus on problem solving, who knows.
(more…)Flexible coding for data visualization


My main-PI has an odd habit of wanting us to edit things as we’re presenting them. I’ve watched this happen and had to do it myself. Suddenly you find yourself editing a paper/grant/etc. and forgetting how to spell your name because you’re so flustered. It isn’t just papers though, it’s our visualizations that we make. He will ask us to go in and change things as they are being shown. This has happened to me several times already and more often than not I’m ready for it. So today I figured I would go over some of the things I do to make sure that I don’t spend the entire time sweating over edits to my code.
(more…)New computer issues…


Well if I’m not a magnet for computer issues I don’t know who is. If it’s not one computer it’s the other. In this case, I had problems a while back with my desktop (here) where the watercooler went bad and my CPU decided it wanted to scream at me anytime I ran the computer, like just turned it on, not doing anything with it. This time it’s my laptop that I’m having trouble with and unlike my desktop, the laptop is my daily use computer so I’m not too happy.
(more…)Fun with Rstudio


Okay, not really. Having to use R is a pain. I’m not a fan and the structure they use is very confusing to me as someone who uses MATLAB on a regular basis. I understand matrices, I regularly make and successfully work with higher dimensional matrices ( > 3, which hurts your brain to think about a 20+ dimensional matrix, but hey whatever gets the job done). R on the other hand feels foreign and the commands feel clunky.
(more…)EEG cleaning progress

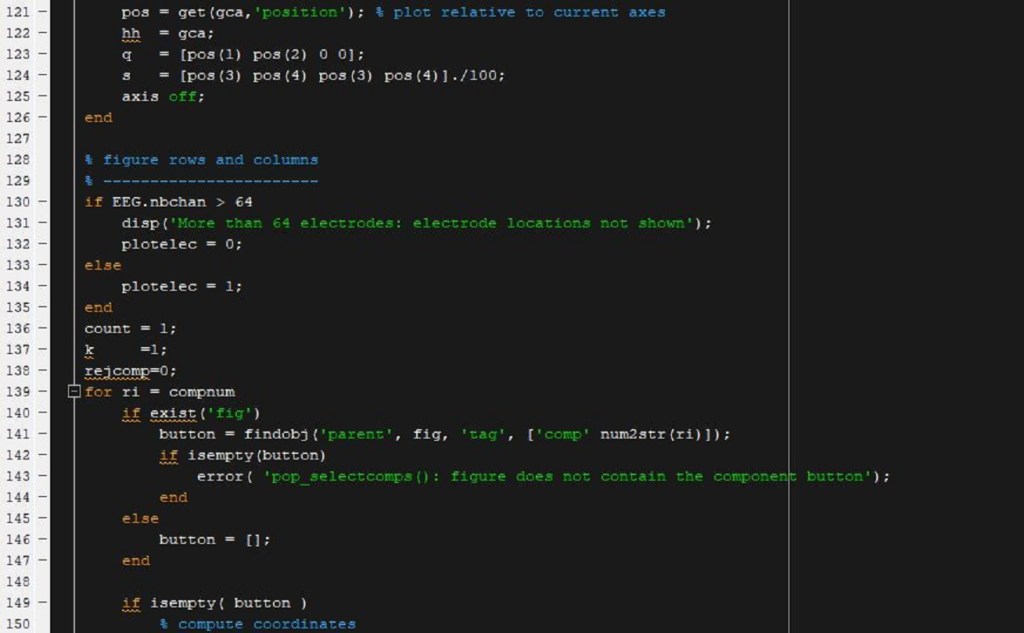
Yesterday’s coding work went better than expected! That may or may not bode will for the rest of the week, but hey at least I’m sort of ahead of schedule. Today I figure we can take a quick look at what I’ve been doing with the data and why. This will be part informative and part me complaining about how everything has to be so damned hard (basically the usual around here). Mostly it will just be some visuals of the things I’ve had to change to get everything looking like my main-PI wants, he’s got a particular style he likes so a lot of large text, bolded labels, etc.
(more…)To code is divine, to err is human
Yesterday we had a problem. My data was not playing nice. It decided that I didn’t really have what I thought I should be seeing and that left me… anxious to say the least. Since this is all so new, one misstep could ruin everything. To make things worse, there was one of three choices and none of them were good news.
(more…)Computer rebuild


Okay, lots of work and not a lot of time to do it in, but today I thought I would show off the internals of my computer since I had to swap out the watercooler for one that wasn’t garbage. This is a follow up to this post, so with the background out of the way, let’s go!
(more…)Time to work


So this post is coming a lot later than I would normally do this, but it’s been a day (already) and it’s going to get busier. I’ve had one experiment, one class, and now I need to repair my computer so I can perform the analysis of the data I have to get done before Thursday. Fun times ahead!
(more…)Computer troubles
I had a feeling this may happen, I just didn’t expect it to happen when I was so against the wire to get this project done. I’m having computer troubles. Not my laptop thankfully, but my desktop computer is feeling a little… warm. I’ll explain and then get into what I’m doing to fix it, so today let’s talk about my computer!
(more…)Day 131: My laptop is ALIVE!


The poor thing has been through a lot, notice my c key is completely worn down. I didn’t know I hit c so hard!
Well after a few days of curing time, my laptop is alive again! In fact I’m writing this on it now. YAY!! I honestly don’t have the money to replace the thing and I already have much needed car repairs to attend to, so this cannot break on me yet.
Day 129: Everything is breaking!!!


Well it’s post Christmas day and I have to say my stealth wrapping was a hit. Of course, after the first gift (or even the second gift) people catch on, but overall it was a lot of fun and I even got a few apologies for some of the ill will based on my apparent lack of wrapping abilities. I HIGHLY recommend giving it a shot. So let’s talk about the image above for a minute.
Day 98: Laptop troubles
Well it finally happened. My laptop looks pretty dead. Right now I have it in pieces while I try to figure out what went wrong with it. Thankfully I have a desktop computer that I use for all my heavy computing as a back up. Just one more expense I guess, I should be grateful that it wasn’t something more serious like the hard drive going out.
So short post, I know, but I have to get this fixed or find some sort of resolution since my laptop is an important part of how I get work done. I’ll have a longer post tomorrow, but for now I think that is it.
Until next time, don’t stop learning!
Day 91: Did that really just happen?

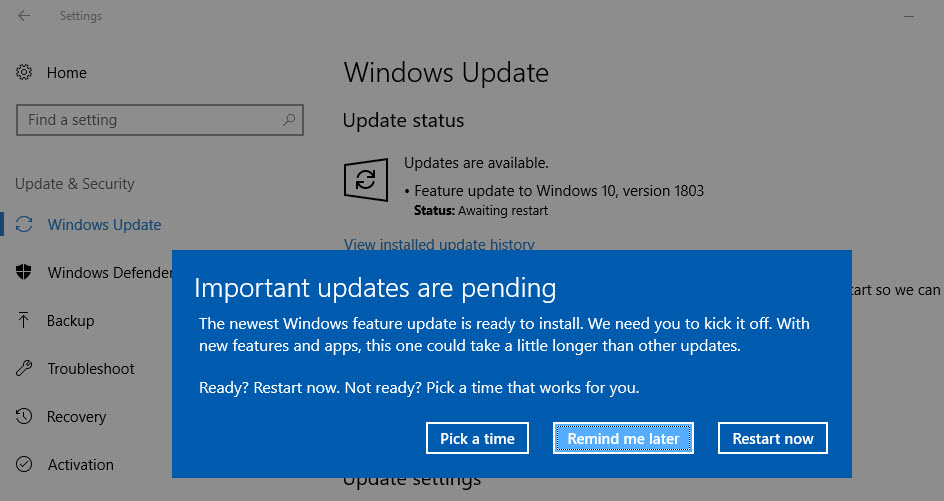
Screw you auto update
For those of you following along, I’ve been trying to crack a predictive model using some novel (read: super secret PhD work) neural data. It’s been a journey and I’ve trained and tested about a dozen or so models, with varying success. Things have been flying pretty smooth the past few weeks as I try to create the best model I could possibly create. Unfortunately, technology had other plans for me.
Day 22: Parametric vs. NonParametric Statistics


Technically we could call this parametric statistics part 2. However, since we are covering nonparametric statistics and more importantly the difference between parametric and nonparametric statistics, it would seem that this title makes more sense. As usual with a continuation, you probably want to start at the beginning where we define parametric statistics. Ready to get started?*
Day 21: Defining Parametric Statistics

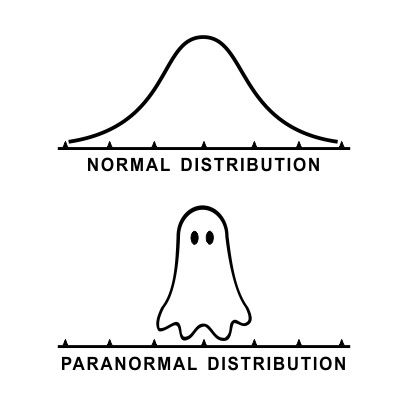
It’s halloween time, we are talking about normally distributed data, so this fits, and I don’t want to hear otherwise!
Well my lovely readers, we’ve made it to the three week mark, 5.7% of the way through! Okay maybe that doesn’t seem like a big deal written like that, but hey it’s progress. So last post we had our independence day, or rather defined what it meant to have independent events vs. dependent events. We also said it was an important assumption in parametric statistics that our events are independent, but then we realized we never defined what parametric statistics even is, oops. So let’s stop dragging our feet and talk parametric statistics!*
Day 20: Independent Events


By: xkcd
Because we introduced the central limit theorem last post, it’s time to introduce another important concept. The idea of independent events, while this may seem intuitive, it is one of the assumptions we make in parametric statistics, another concept we will define, but for now let’s jump into independence.*
Day 19: The Central Limit theorem


Well here we are again, if you recall from our last post, we talked Bonferroni Correction. You may also recall that when the post concluded, there was no real topic for today. Well after some ruminating, before we jump into more statistics, we should talk about the central limit theorem. So let’s do a quick dive into what that is and why you should know it!*
Day 18: The Bonferroni Correction


By now we are masters of statistics… right? Okay, not really, but we are getting there. So far we’ve covered two types of errors, type 1 which you can read about here, and type 2 which you can read about here. Armed with this new knowledge we can break into a way to correct for type 1 errors that come about from multiple comparisons. Sound confusing? Well, not for long, let’s break it down and talk Bonferroni.*
Day 17: Type 2 errors


Last post we did a quick bit on type 1 errors. As with anything, there is more than one way to make an error. Today we are talking type 2 errors! They are related in the sense and we’ll go over what that means and compare the two right… now!*
Day 16: Type 1 errors


We did it, we cracked the coin conundrum! We managed the money mystery! We checked the change charade! We … well you get the idea. Last post we (finally) determined if our coin was bias or not. Don’t worry, I won’t spoil it for you if you haven’t read it yet. I actually enjoyed working through a completely made up problem, so if you haven’t read it, you really should. Today we’re going to talk dogs, you’ll see what I mean, so let’s dive in.*
Day 15: Significance, Part 3

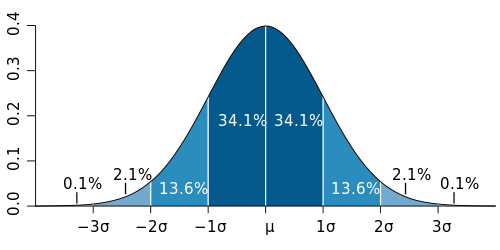
Where does our observation fall on the probability density function?
It looks like we’ve arrived at part 3 of what is now officially a trilogy of posts on statistical significance. There is so much more to say I don’t want to quite call this the conclusion. Instead, let’s give a quick review of where we left off and we can get back to determining if an observed value is significant.*
Day 14: Significance, Part 2

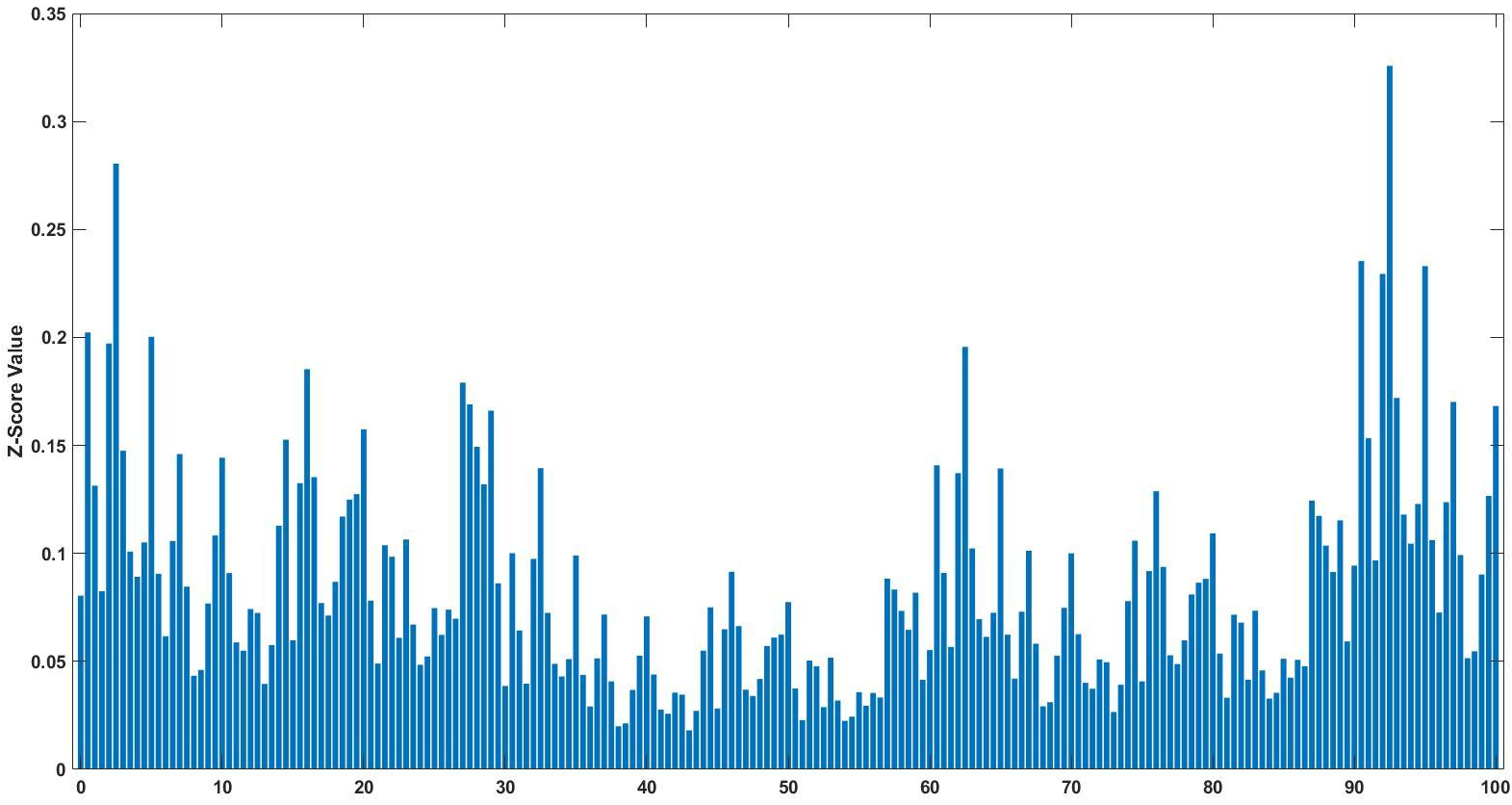
Z-score bar graph that I made just for all of you using some data I had laying around. If you’re new to statistics it may not make sense, but rest assured we will make sense of it all!
Well here we are two weeks into 365DoA, I was excited until I realized that puts us at 3.8356% of the way done. So if you remember from last post we’ve started our significance talk, as in what does it mean to have a value that is significant, what does that mean exactly, and how to do we find out? Today is the day I finally break, we’re going to have to do some math. Despite my best efforts I don’t think we can finish the significance discussion without it and still manage to make sense. With that, let’s just dive in.*
Day 13: Significance, Part 1

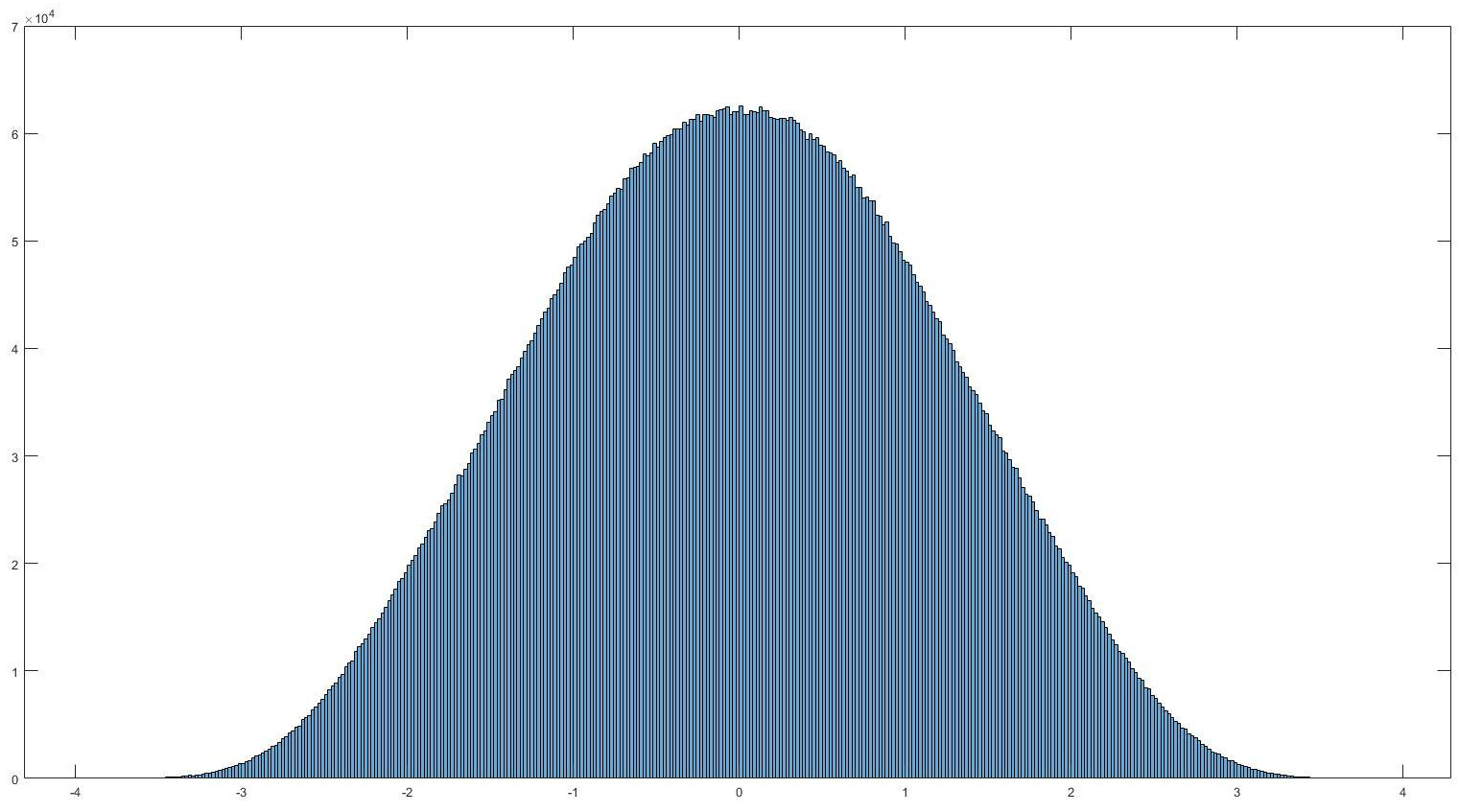
Histogram of normally distributed data. It looks very… nomal. No it really is normally distributed, read on to find out what that means and how we can use it.
If you’ve read my last post I hinted that today we would discuss filtering. Instead I think I want to take this a different direction. That isn’t to say we won’t go over filtering, we most definitely will. Today I want to cover something else though, significance. So you’ve recorded your signal, took an ensemble average, and now how do we tell if it actually means something, or if you are looking at an artificial or arbitrary separation in your data (IE two separate conditions lead to no difference in your data). Let’s look at significance.*
Day 12: Signal, cutting through the noise

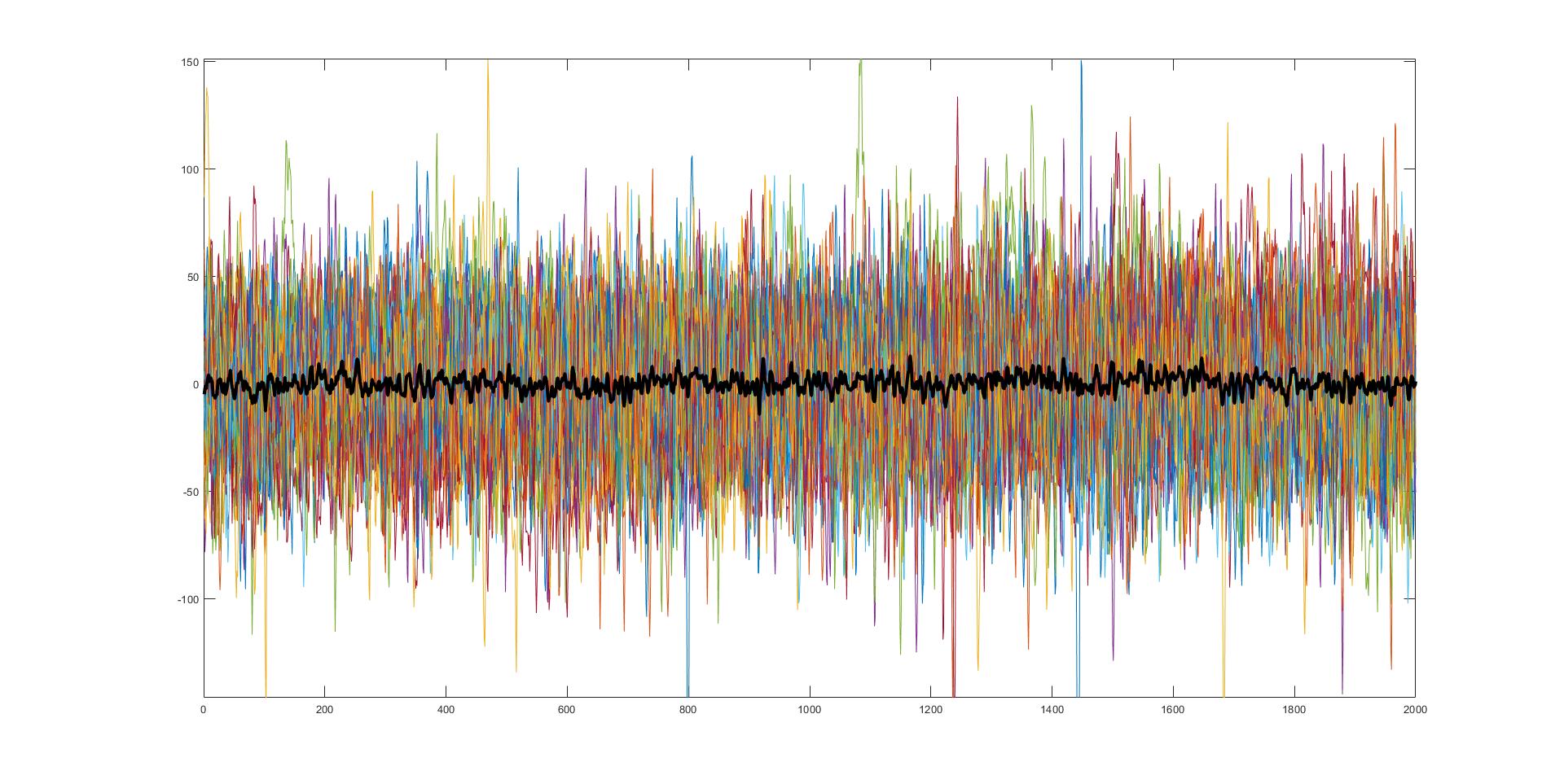
45 separate trials of very noisy data with the average of those trials (black). Believe it or not, this is actually very useful and very real data from something I am currently working on.
Noise, it can be troublesome. Whether you are studying and someone is being loud or you are trying to record something, noise is everywhere <stern look at people who talk during movies>. Interestingly enough the concept of noise in a signal recording sense isn’t all too different from dealing with talkative movie goers, so let’s talk noise!*
Day 11: Why even use the spectrogram?

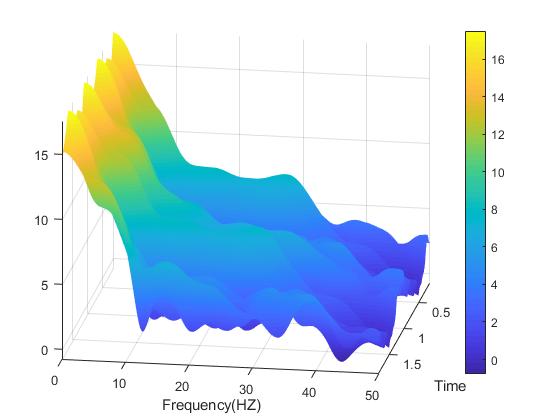
A spectrogram plot rotated so we can see all three dimensions.
So you wanna use a spectrogram… but why? What does a spectrogram do that we can’t do using some other methods for signal processing? As it turns out, there is a lot of reasons you may want to use the spectrogram and today we are going to cover some of those reasons and number four may shock you! (okay not really, what do you think this is a clickbait website?)*
Day 10: Spectrogram vs. the banana of uncertainty

The banana of uncertainty (okay, it’s not a real banana)
Well ten days in and we’ve just introduced the idea of the spectrogram. While a lot of this information is just the broad strokes, I like to think that we’ve covered enough to give you a good idea about how to use these tools and what they are used for. However, we do need to discuss a limitation to the spectrogram, something called the banana of uncertainty, okay not quite the name, but you’ll see why I keep calling it that.*
Day 9: Reading a Spectrogram
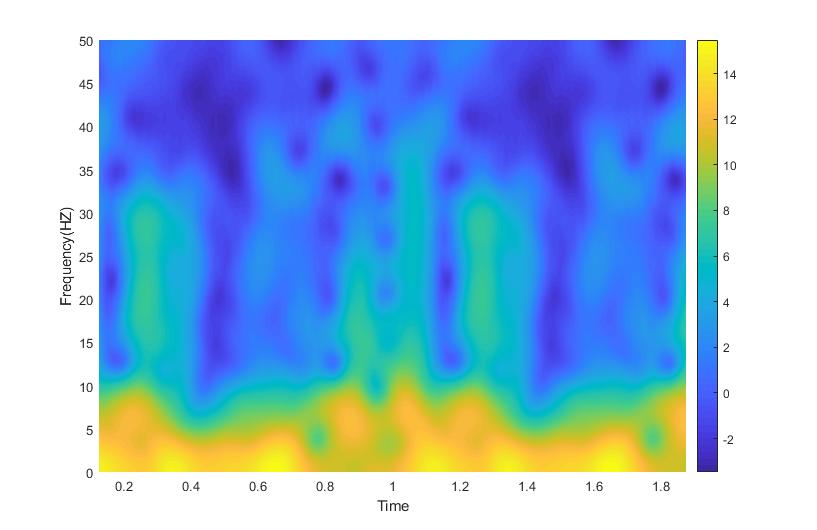
Definitely not the same spectrogram as yesterday, no really look. Now for the part where I tell you how to read this thing…
Last post we introduced a new tool in our arsenal of signal processing analysis, the spectrogram. Without knowing how to read it, it just looks sort of like a colored mess. Don’t get me wrong, it is an interesting looking colored mess, but a mess nonetheless. Well today we are going to talk about how to interpret the plot and why exactly we would ever use this seeming monstrosity.*
Day 8: The Spectrogram Function


Example spectrogram from some data I had recently processed
To (somewhat) continue with our signal processing theme that we have going on at the moment, over the next few days, let’s look at something called the spectrogram. It’s three dimensions of fun!*
Day 7: Small waves, or wavelets!

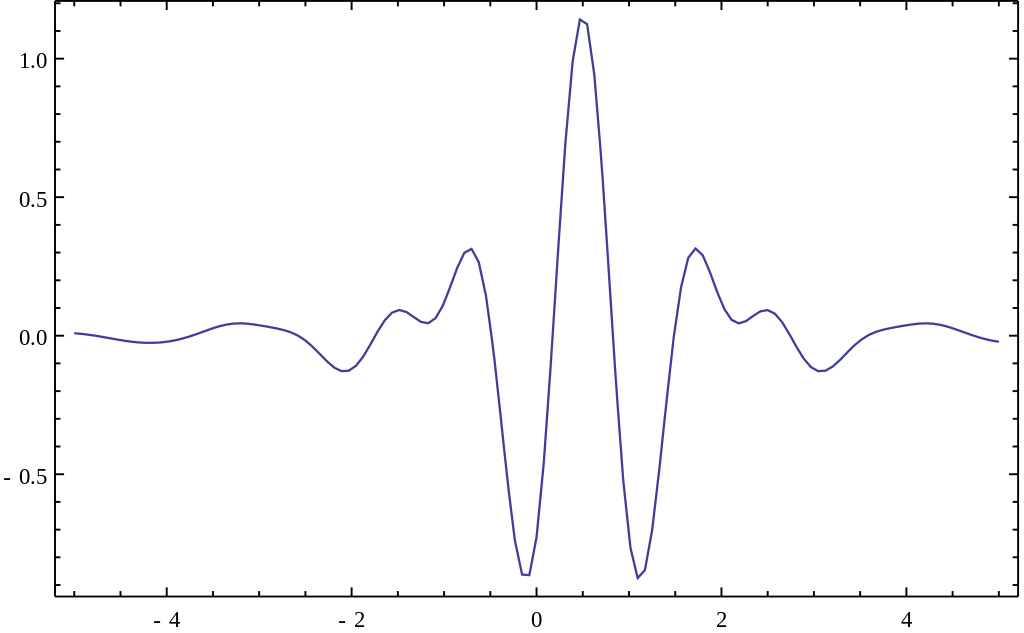
This is the Meyer wave, a representation of a so-called mother wavelet function to use for the wavelet transform. Notice that it is finite!
Waves! We’re officially one week through 365 Days of Academia! Woo! 1 week down, 51(.142…) weeks left! Let’s wrap up this weeks theme (there wasn’t originally a theme, but it kind of ended up that way) by talking about other ways we can get to the frequency domain. Specifically, let’s stop the wave puns and let’s talk wavelets!*
Day 6: The fast and the Fourier
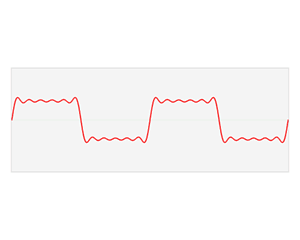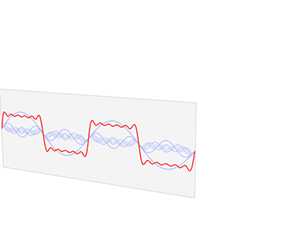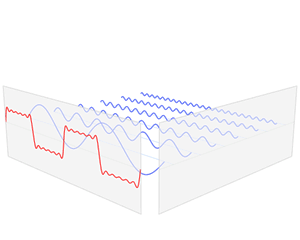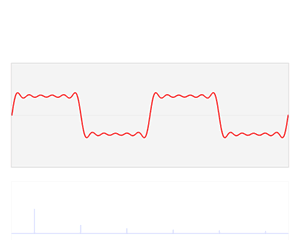
A good example of how the Fourier transform can approximate signals. The red signal is our input signal and the blue shows how the output of the Fourier transform.
Okay, if you’ve been keeping up with these posts, we know about Welch’s method, Thomson’s method, the things that make them different, and the things that make them similar. The thing that both of these transforms rely on is the Fourier transform. What is the Fourier transform? Well, something I probably should have covered first, but whatever this is my blog we do it in whatever order we feel like, so let’s dive in!*


