Day 84: Model training progress
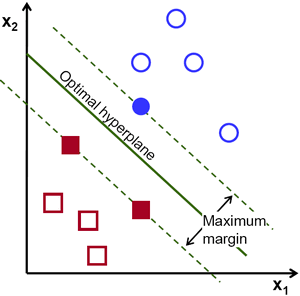
Two dimensional data is easier to visualize than 202 dimensional data.
I don’t normally leave my computer on 24 hours a day, but it has been hard a work, so it hasn’t been off in days. Training a model can take some time, as I am finding out and while I’ve made progress on the resulting model, it’s still not where I want it. Let’s talk about what has been going on.
If you recall, my post a few days ago covered what I’ve been up to these past few days. It’s been all over the place and I’ve had several setbacks. Mostly my computer froze, so I had to restart it and reload all my data (this wasn’t hard, but it was frustrating). There is a lot of setting my parameters and walking away from the computer for a few hours while it trains, so coming back to absolutely nothing did not make me happy.
I do have good news regarding the progress though! I’ve changed up my parameters and I’m getting somewhat better results. I’m currently using a SVM classifier, SVM or support vector machine classifier. SVM classifiers try to find a hyperplane that best separates the classes (a hyperplane is just a plane in higher dimensional space, let’s see what that looks like (courtesy of the example image mathworks gives)
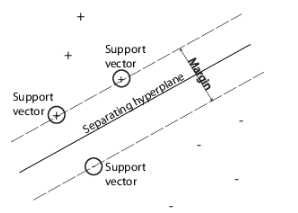
How we separate our classes
In this case, the support vectors are just the values closest to the separating hyperplane, in this two dimensional case it is easy to visualize, in my 202 dimensional space, not so much. Now there are several ways we can draw the plane and that determines the result. We can use a linear hyperplane to separate the classes (which is a fancy way of saying a straight line, like the one you see above). However, we can get more complex with the geometry of the plane, we can use a quadratic, cubic, or Gaussian just to name a few examples.
SVM have the benefit of being fast (for binary classes at least), however the interpretability is not easy (meaning I have no idea how my model came up with the solution it did), with the exception of the linear model that is, but that is because it is linear so making sense of it is a little easier because the math behind the linear hyperplane is simple relative to the other types of SVM classifier.
Now SVM modeling isn’t the only one we can use, it just happens to be the most appropriate here, we also have decision trees, discrimination analysis, logical regression, and nearest neighbors to name just a few. They all have benefits and downsides, but the biggest factor in selecting your model type is just the type of problem you are trying to solve.
Unfortunately when it comes to models, the type is just the first big choice you need to make, there are tons of options and ways to use the model you selected. For example, I’ve tried about 10 different SVM models, mostly Gaussian. Now I am attempting something that froze my computer last time I did it. I’m trying to optimize my model, this will adjust my parameters for me and chose the ones that give the best outcome. So far it hasn’t froze, so fingers crossed.
As for my progress? Well I’ve gone from a very overfit model to something that is claiming high accuracy, but gives me mixed results when I feed in my data. It is however predicting my second class (my one instead of all zeros like one of my first attempts at creating a model gave me). Here is where I am now, the red is my actual classes (my labels for my test data) and the blue is my predicted classes. Remember, the model has never seen this data, so it is making a prediction solely from the training data (this means I won’t overfit my model by testing with the same data I trained with).
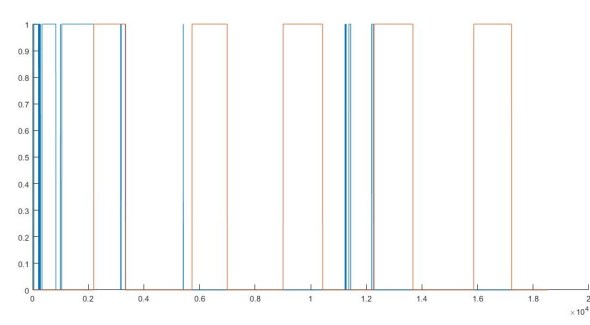
My (horrible) model prediction rate
Not great, but it’s a step in the right direction at least. Here is the kicker though, the Here is what my prediction accuracy according to my training.

Training accuracy of my model (3 is the model I used for the data above)
Yeah, I’m training my new model and optimizing it, but right above that, that is the model I used with this data. 99.9% accuracy (supposedly), but basically garbage with my new data. I’m hoping that optimizing my model will give me better predictive power, we will see. Hopefully I’ll have some good news in the next day or two.
Until next time, don’t stop learning!



But enough about us, what about you?