Day 81: Creating a Model
Today is going to be a long day. I’m training a model using some data I’ve collected. Now, depending on your background that sentence either meant something to you or was complete gibberish. In either case, let’s talk about what I’m doing, even though I can’t get into specifics about my data.
I’m the black sheep of the lab, I work in a brain-machine interface lab and I do not work with the brain and I do not create the machines we interface with. To be fair, I am doing neural-machine interface work, just not the same stuff the rest of the lab is working on. Today is training day and my computer is doing the heavy lifting as I’m typing this.
For those without a background in machine learning (which is really a fancy way of saying optimization, I mean come on), I’m feeding binary data into a classifier to create a predictive model using a bunch of data I have that I’ve labeled into my two classes.
Now in this case a class is just whatever you want, red/blue, up/down, on/off, these are binary class examples. In my case, I’ve sorted my data, gave it a label, and am currently feeding it into an algorithm for it to determine the best way to seperate the two classes.
There are several ways to do this, linear classifiers, which will draw a straight line (hence linear) down the two classes to divide them as best as possible, if the data point falls on one side of the line it is in that class, if it falls on the other, it belongs to the other class. This works well in lots of cases, but I’m not getting the results I want from it. I’m aiming for ~95% classification accuracy and I’m hitting a (in comparison) paltry 76.8%.
So now it’s off to non-linear classifiers, where the algorithm will draw a nice wavy line (for lack of a more technical term) to segment my data classes. This is more accurate in a lot of cases because your data are not going to be grouped in two distinct classes (more often than not), you are going to end up with overlap, sometimes significant overlap, so drawing a non-linear line (or multi dimensional plane really) will let you better break up the overlap. The trade off is that this can take forever.
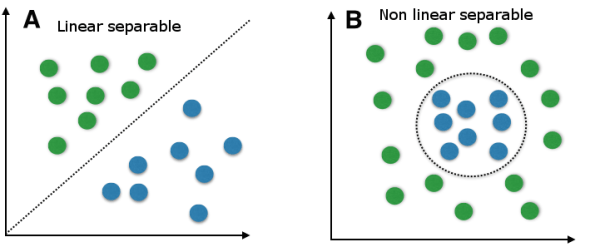
A linear classifier vs. non-linear classifier, the best choice is based on your data, but these are two dimensional examples, so you can visualize them, I’m working with 101 dimensions, so I can’t check them like this, I need to train different models to check.
I’m working with 101 dimensional data, now don’t confuse that with spatial dimensions, in this case a dimension just means a different type of measurement. So if we wanted to classify apples and oranges we could have several dimensions, for example color, shape, size, weight, texture, etc. These would all be different dimensions, so don’t think it has to be limited to spacial dimensions (although you can include those too if you wanted).
To be fair, this isn’t a very high dimensional dataset, I could have 1000’s of dimensions if I wanted or I could use math (specifically principle component analysis or PCA) to determine which of my dimensions are most significantly contributing to the classification, for example if we go back to our apples and oranges classifier, weight might not be a very good way to predict apples and oranges, they may have the same range of weights, so PCA might get rid of that dimension since it isn’t helping.
In any case, once I have my model I will feed it data I’ve set aside, data it hasn’t seen. Why would I do that? Well this prevents overfitting, say I have two dimensions and plot the two things I’m trying to classify, I COULD artificially draw a line in such a way that I get 100% accuracy. However, this is an overfit model because the second I give it new data, that new dataset might not be predicted at 100%, see the image below for what I mean. To avoid this, we train a model with a lot of data (the more the better), then we give it data it hasn’t seen to test the accuracy of the model, this is how we determine how good of a model we have.
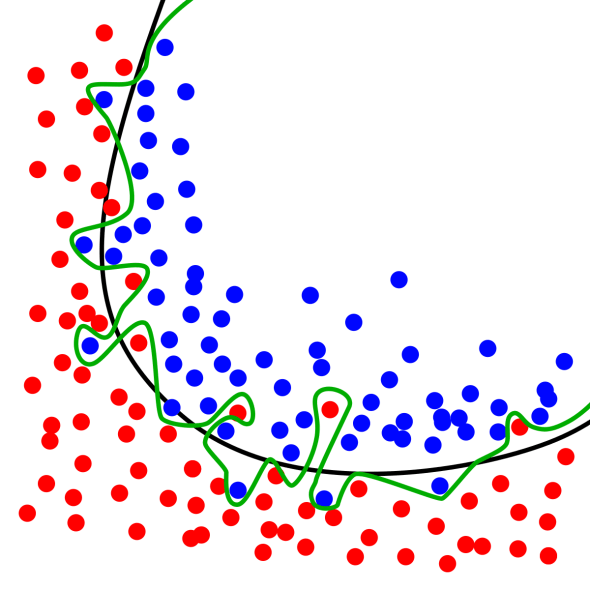
The black line doesn’t give us a 100% accuracy, but it is better at prediction than our green line which artificially gives us 100% prediction accuracy.
Right now, I’m still on the training bit, but in about 2-3 hours (if I’m lucky) I will have a new model to test on my new data. Thankfully once my model is trained the prediction portion goes pretty quick (minutes not hours). There are other types of classifiers as well, it doesn’t have to be binary, we could have multiple classes, it just depends on what you are trying to do.
I think we will get more into classifiers here later, but for now, I’ve got work to do and I don’t want to confuse anyone more than I might have already. This may be a brief introduction into classification, but you could spend years learning and not know everything there is to know, so let’s take it a little slow.
Until next time, don’t stop learning!



But enough about us, what about you?