Day 82: Congrats, it’s an overfit model
There I was patiently waiting for my data to finish being processed, an hour, two, time kept moving as did the little animation letting me know that the algorithm was still doing its thing. Then it was done, I had a new, more complete model and it was glorious… until it wasn’t.
My first attempt at classifying my data led me to a good, but not great accuracy rate of ~78%. Not bad, but I was aiming for something a little higher, high 80% or even low 90% if I could help it. So I went back, changed a few parameters and tried, and tried, and tried.
For my first model I had fed in only half of my data, the more relevant half (or what I assumed was the more relevant half). So to hopefully increase my accuracy I wanted to feed in more data, I fed it all of the data this time. I also gave it a extra rather large chunk of data where my subject was at rest. I was hoping that my classifier would use it to see that at rest nothing is really changing so it’s an easier way to tell on from off.
This not only doubled the data I was feeding in, after all I went from 101 dimensional data to 202 dimensional data, but it also significantly increased the data length, by roughly 120,000 samples. So now I had 202 dimensions and almost 300,000 data samples to train my model. It was going to be perfect this time.
So after manually checking and double checking my class labels (an arduous task to say the least), I gave the algorithm my data and trusted the process. I was rewarded this morning with a beautiful model. It was perfect, well not quite perfect, but it had a 99.8% accuracy rate. It was exactly what I wanted and best of all I didn’t have to optimize it to get the result, I was vindicated!
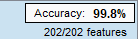
It’s perfect!! … oh wait no not really.
Next was the big test, test my new trained model with data it never saw. This would tell me if I had a good model, or a dud. I input test data with five instances of my on class and I crossed my fingers that the model would find these five instances and return the predictions with the stunning precision it had promised me when I was training my data.
Nothing.
No really, I gave it my data and the prediction was all my off class (which I labeled as zero) so I had a nice plot of a straight line from start to finish at zero. Not quite what I had hoped for. My high hopes were dashed. After some thought, I decided to pull out the extra rest data, the 120,000 extra samples of my zero class was certainly the cause of the issue… right?
The thought process behind it was that I had performed k-fold cross validation to prevent overfitting of my model. K-fold cross validation works by setting aside a small chunk of my data, then it trains my model with the large remaining set and repeats this k times by separating my data into k chunks and setting aside a different one each time to test with. Then in the end, it picks the model that had the best accuracy.
I had performed 9 fold cross validation, so it broke my data into 9 sets, trained on 1-8, tested on 9 then trained on 2-9 and tested on 1, and so on. I had assumed that it broke my rest chunk almost exclusively into a chunk and selected the model that predicted absolutely nothing because for the entire rest set, there was nothing to predict. That was an easy fix…
In the wee hours of the morning, I toiled away (okay not really, this part was simple, I just tacked the data on at the end of my training set, so I just removed it just as easy). Next, I refed the data into the classifier and after several long, long, loooooong hours it had finished training and I had my new model. This time I was suspicious, but again it taunted me with a 99.8% accuracy. Suspicious and with my expectations set nice and low, I gave it my test data, again data my model had never seen and it returned its prediction.
This time it actually predicted my second class (which I labeled as class 1), but it didn’t get anywhere close to the actual portions of my data where it should have labeled as class 1.
Gurr… so now it’s time for more drastic measures. Okay not really, but I do need to come at this a different way. I’ve changed my model around (remember this dictates how my hyperplane will be drawn, from a straight plane, to a super curvy and warped one) and I’m currently (as in at this moment) trying again.
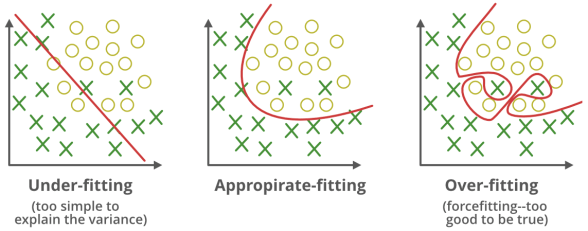
Clearly my model was overfit. It accurately segmented my training data, but had no idea what to do with data it’s never seen before. Which to be fair, is why we have some test data set aside. Meaning that the process works at least, I mean of course it does, but it’s nice to have some confirmation instead of just blindly trusting. What’s next you ask? Well, I’ve relaxed some of the parameters that could’ve caused the overfitting and I suspect that it will return something to me that isn’t as high accuracy, but ideally it will be something that will better predict my new data. And now we wait…
Until next time, don’t stop learning!



But enough about us, what about you?