There was trouble, because we didn’t make it double


If you want horrible and possibly dated Pokémon puns, I don’t have any. What I do have is a set of skills, skills that make me a nightmare for … well myself frankly and even more horrible possibly dated other puns that have been… taken? The time to graduation is coming, three weeks left, less than three weeks frankly, three weeks last Friday, so like 2.5 weeks-ish. Well have I got a story to tell! I wish it were good news, and in some ways it is, but in other ways, not so much. Don’t worry I’ll break it down a bit so we can get the weekly window view of what’s been happening behind the scenes during my (mostly) radio silent era.
(more…)Four weeks and counting!


Well okay to be honest not exactly four, less than four. Oh no, my defense is less than four weeks away. This feels a bit odd… but here we are I guess. It seems like I’m never going to finish, but there has been progress! Setbacks too for sure, but progress nevertheless! Since it’s so close and I’m in a huge panic ALL THE TIME! I guess (reluctantly…) we can discuss the progress that has been made and what’s left for us as I approach the first of the next major deadlines, the format check. Which is just a week away if my calendar is correct (if not, well than oops…).
(more…)The missing months


Well, there goes the project. Okay not really, progress doesn’t reset, it’s not all or nothing. So there’s a gap, I stepped away for a minute and boom it’s been a few months since I last wrote anything. It’s odd because it doesn’t feel that long. I almost got into the habit of telling myself that I would write about something as soon as I had something to write about. Well I’ve never been at a loss for topics, so it was more of an excuse than a reason to not blog. To be fair the time away has helped, but it also made me miss doing this. So let’s talk about the missing months, shall we?
(more…)Return of the long experiment


It’s been awhile! Things have been busy so I’ve had to prioritize what I wanted to get done to avoid the crash I had after the DARPA event at the end of last year. So there’s a lot of updates coming, obviously. I still want to blog and I hope to get back into the daily routine soon enough, but I wouldn’t be surprised if it didn’t happen this week, because this week it’s the return of the long experiment. So let’s break it down a bit and talk about why this round will be different than the previous versions. Well as much as I can talk about anything I’ve been doing anyway.
(more…)The road forward


Well, it’s been a journey. As I keep mentioning, it’s not over yet, but I can’t help but look back at some of the first few years of posts where I felt lost and/or hopeless. Things have a tendency to work out and I knew it then just like I know it now, but I won’t lie and say it’s been easy. Between now and graduation there is still significant work to be done, but now that I’ve crossed the last week off my list it feels slightly more manageable. I still feel a bit like I lost something, even after gaining a whole lot, but I think that comes with any long-term accomplishment and I should probably brace myself for the feeling to hit again when I finally get my degree. Hopefully, it still feels like something that may not happen for whatever reason.
(more…)AHHH!! Real zombies!


It’s my favorite post of the year!!! Every year I update and post my favorite Halloween Lunatic Labs tradition! Ironically with everything going on this year I almost forgot to post it, which seems to have been the case last year as well (see the theme?!)! In any case, today we bring you the science fact behind the undead. Zombies, those brain loving little things are everywhere. Sure, we are all familiar with the classic zombie, but did you know that we aren’t the only zombie lovers out there? It turns out that nature has its own special types of zombies, but this isn’t a science fiction movie, this is zombie science fact! And sometimes fact can be scarier than fiction. Now, let’s talk zombies!
(more…)The second crunch


It’s that time again, crunch time! I think it may be easier to just blog about days that aren’t crunch time honestly, because at this point you could call me captain crunch (legally obligated to ask you not to do that). Grad school can be painful, but we’re close to the end and that may be the biggest problem. There’s just too much to do in the timeframe I want to do it all in. A lot of this cannot be automated, so late nights and long days are abundant. But tomorrow is the second finish line and depending on what I can get done today, we will at least cross it with a modicum of grace. Well except for the surprise demo that is.
(more…)The work continues


Yesterday I mentioned all the work that was ahead for me. And work there is! While I have one dataset done (mostly) I need to process the rest of the data (ideally) to make my deadlines. Not all the data needs to be processed, but most of it would be nice, all of it would be great, and right now I have exactly no data processed so I am not exactly sure how much I’ll be able to finish today. Sometimes that’s just how these things go though.
(more…)The next dissertation steps


Well it’s the weekend! Which means work, because of course it does. If it weren’t for the fact that I’m doing both work-work (as in working in a hospital) and PhD work (school), I would have my weekends (mostly) free for myself, but since I want to graduate soon, there’s a lot that needs to happen. Order of operations matter and today I’m going to talk about my plan to get the first phase of my dissertation data finalized. And it needs to happen quickly!
(more…)A long conclusion


We did it, another “long experiment” in the books. Total time? Twelve hours. Twelve, non-stop. Okay there was exactly one bathroom break, one coffee drank and one protein bar eaten, but I kid you not, that was all there was time for. When I say long experiment, I mean LOOOOOONG experiment. 98% of that is standing, well moving around doing things, so let’s say “not seated” since that’s more accurate. So, was it worth it? Well now, that’s the real question isn’t it?
(more…)The last day of prep


Well I’m not pulling an all nighter today so that’s good news. Two weeks ago we had our first “long experiment,” now we’re going into the second one. Long experiment because it will take all day and I mean all day. We start at 7am and I’ll be lucky if we finish at 7pm, that kind of long. Since long experiment is, well long, I’ve been working on lots of different ways to optimize the experiment. That won’t make it shorter, but I’m hoping it will be less stressful.
(more…)When the assumptions fail


We make simplifying assumptions all the time. Assume the cow is a sphere. Assume a frictionless surface. Assume no air resistance. If you’ve ever taken a physics course, you’ve run into these at least once. Simplifying assumptions work because they get us an answer that is close enough to the “true” answer that we don’t need to do all the extra work of finding a more complex high accuracy solution. We like assumptions because they make our lives easier! But what happens when your simplifying assumptions turn out to be incorrect?
(more…)The next countdown


Well the next long experiment is slowly coming and by slowly I mean AHHHHHHH!!! It’s only a few days away!!!!!! What are we going to do, someone panic and use more exclamation points!!!!!!! Seriously though, we’re counting down to the next long experiment and hospital-PI is already quizzing me to make sure we’re ready. This needs to go off without a hitch, but as we know the best way to ruin a plan is to try and execute it. Well there’s no substitute for practice… I guess?
(more…)Return to the OR


It’s been a minute since I’ve had an OR experiment. To be fair there’s a lot going on and with the stuff we’ve been doing there hasn’t been time. But there’s also the participant factor. People need to agree to be part of the study and even before then we need to make sure they are a good fit, so there’s a lot of factors for why we haven’t done one for some time. In any case that is quickly about to change!
(more…)The long week ahead


It’s going to be a looooong week. Mostly because we have what I’m calling “long experiments” coming up this week. Which of course has a lot of work attached to them. When I say long, I mean all day, all day experiments are intense and there’s still work to be done. So this week is mostly going to be focusing on the remaining work I have. But it wouldn’t be a long week if there wasn’t other stuff coming, meaning we have experiments, classes, and a whole lot of other stuff to look forward to in the week ahead.
(more…)The slow progress


It’s been a very long day, but somehow not a lot got done. Ever have one of those days? The kind where you’re working from sunup to sundown and somehow nothing got accomplished. I guess there was forward progress, but it feels too slow and right now, I really can’t afford to go slow. If I’m lucky, tomorrow will be better, if not, well then I’m not sure.
(more…)The long preparations


As promised, I’m already preparing for the next “long” experiment. This one will be just as long as the previous, if not longer, so we need to be using our time the best way possible. Ideally we’ll be getting all the data, all of it! But to do that we’re going to need a lot of work between now and then. Part of that will be working out some new code to automate a lot of the stuff we’re trying to do, but some of it will involve making things, because of course it will.
(more…)Another big iteration


Well I’ve barely got the second generation of my “big idea” done, in fact it’s not even completely finished yet, but I’ve already got plans for another iteration. There are several parts involved in making this happen and there are always ways to improve upon the design and create something better. So, with the first round done and tested and the second being completed, I’m already thinking about what to do next. Would it be too much to say it’s going to be… big?
(more…)The looooong experiment


Ever have one of those nights where you KNOW that tomorrow you have a huge thing going on and for whatever reason, you just CANNOT sleep to save your life? Maybe it was because every few minutes I was reminded of something I needed to do prior to the experiment, or maybe it was just because there was already so many things left undone. Whatever the reason, what should’ve been a day for me to get a full night’s rest turned into what amounts to a power nap.
(more…)The day before tomorrow


It’s basically the big day at this point and I still have a bit of work ahead of me before the official kick off. We have a very strict schedule and I need to make sure that things go smoothly, or as smoothly as possible. I’m not going to lie, we’re already off to a bad start. It’s going to be rocky and we have a whole 12 hours or so for the electrical gremlins to get into the equipment. The pressure is on!
(more…)Experimental prep: part 2


I feel like a broken record at this point, buuuuut… it’s been one hell of a day. It’s been non-stop go, go, go and there’s still one day between now and the big event. There’s still a lot of work to be done and I’m not sure how long it will take, but I have a feeling tomorrow will be a very long day. In fact, these next few weeks will be some of the hardest in recent memory and that’s saying something.
(more…)Experimental prep: part 1


Okay there’s a few days between now and the incredibly complex and labor intensive experiments we have coming up on Friday, so there’s a high chance that this will be a multi-part discussion, hence the title of the post for the day. We’re rapidly approaching the big day and there’s so much work that needs to happen I’m starting to get a little nervous that I have enough time to do it all. To add to the chaos, there are other experiments happening, that require equipment that we’ll be using for Friday, so there’s no way to setup early.
(more…)Dissertation data update 1


I’m being lazy so we’re just going to number my updates with regards to the dissertation data I collected, because I’m tired and I can’t honestly think of a better way to do it at the moment. This is subject to change if I come up with a more creative way. So a while back I collected a bunch of data, then this weekend I had my first chance to teach the people who assisted the first steps to processing it. It turns out there’s a long way to go with them.
(more…)Success! 8 of 10 dissertation experiments


Well today was the day that would never end. I only had one experiment today, but it took the whole day. To be fair, we didn’t start until the afternoon, but it was well into the evening when we wrapped up and that was exhausting. Since it’s been such a long day, I’ll recap how things went. For everyone who’s interested, but also for myself since I hope this will help with my dissertation writing sooner or later.
(more…)Equipment modding time


Well today was a long day, but something good came out of all the running around. Some of my new equipment showed up, which will improve how I do the experiments that I want to do, but also make my life so much easier, like way easier. Unfortunately, the usual applies,I can’t talk about it directly, but it’s a good time to discuss how ideas evolve and how you find ways to improve things as you go!
(more…)More coding adventures


It’s another day and another chance to make progress with data processing. Since it’s been a busy few weeks since hospital-PI has returned to the lab, I haven’t had a ton of time to work on the dataset that we collected, the first of hopefully many. However, the initial analysis is done, so it’s time to move forward and start thinking about what comes next. That is, how can we refine what we’ve done? There’s a lot of steps I can take, but I think today we’ll sum it up and narrow it down to the steps I’m most excited about.
(more…)The helping hands


So granted it’s my blog, my journey, and basically all about me, so maybe I think too highly of myself. I’m trying to not read too much into the implications and what that says about me, but I’ve always thought of the blog as more of a tracker for myself than anyone else. Not that I’m not happy to have the company! Today though, I thought it would be nice to talk about why it takes a village to make a dissertation, despite what it may sound like sometimes.
(more…)Success! 7 of 10 dissertation experiments


One more time. Well technically it’s two days, but whatever. Today marks the completion of 7 of the 10 dissertation experiments I need to get done! Wow, things are moving quick, but maybe not quick enough considering I still need, you know, process the data and make sense of it all. But that’s tomorrow’s problem and I don’t have to worry about that today. Let’s talk a bit about how today went though!
(more…)The internal scars


Not all trauma leaves a visible mark. Just like not everyone who is disabled “looks” disabled, not everyone who has had a traumatic event, even a very physical one, will have scars that show. That doesn’t mean they aren’t there, or that if you look hard enough you can’t find evidence of them, it’s just not a big flashing neon sign saying, “here I am!” It also doesn’t make them hurt any less, or make them any less real. Sometimes the trauma you can’t see is the trauma that hurts the most to carry.
(more…)Success! 1 of 10 dissertation experiments


What a day… I’m so exhausted. It’s been such an overwhelming amount of work, but it’s over and that’s one of the ten experiments I need (for the first phase of my dissertation anyway) done. The data collection went smooth, I love the new equipment, and I only ran into what appears to be one problem with the recording, but I’m hoping it wasn’t a real issue. So quick recap of how it went and then I get to remind everyone, and myself, that I get to enjoy doing it all again tomorrow!
(more…)The first equipment test!


It’s been literally months in the making, but we finally have the equipment I need to start my dissertation and even though it’s the weekend, I’m making a special trip to campus (it’s been like a month since I’ve been there) to test out the equipment and get things ready for my first set of dissertation experiments! I’m hoping things go smoothly so that I can get the data needed, but as with all things, some assembly is required.
(more…)The last day of summer internship


Today marks the big day! It’s the last day of the summer internship at the hospital and the two individuals we got to work with over the summer are about to present their final work. It is going to be a busy day for everyone involved, myself included. Since I haven’t got to talk about our interns this year, I thought it would be great to go over some of the stuff we did with them.
(more…)Return of the experiment gremlins


Maybe the moon was not in the correct spot. Maybe the earth’s tilt was not optimal. Maybe we should’ve just called it a day. But for whatever reason, anything that could go wrong, did. We do our best to prep for these kind of events, but some days, nothing goes right. Today was one of those days and as frustrating as it can be for the experimenter, I’m sure our participant wasn’t thrilled about the constant problems either.
(more…)A wait off


See what I did there, again? Yesterday I lamented that I was waiting, and waiting, and waiting, but Godot never seemed to show up. Wait wrong story. But seriously, I have been waiting months for equipment so I could start my dissertation data collection. THE final thing. I can’t begin to put into words how frustrating this whole process is, I’m ready to do something, like now! I want to do it, the will is there, but the equipment isn’t. So what to do, but wait and wait some more, unless…
(more…)Presentation work


Despite all the stuff that’s been going on the past few days, I’ve been tasked with making a video for school side of the two conferences I need to attend. It’s not a bad thing, but there’s some extra work involved and there’s a bit of a timing issue. No one said doing all this at once would be easy. Even with all the stuff going on, we’ve got work to do.
(more…)Death, consent, and Einstein


Death and taxes, the two constants of the world. I think some people are afraid of death because it’s so common, so… pedestrian. We all do it, wealthy, poor, unlike almost everything about life, death is the great equalizer. In life we are taught we have choices and those choices are set by our circumstances, but for the most part we get to decide what our lives look like. Unfortunately, that isn’t always the case when we die, even when our wishes are made explicit. This is the true story of the death of Albert Einstein and if you don’t know it, I don’t blame you if you don’t believe it.
(more…)The mechanisms of depression


In news that will surprise almost zero depressed people, we are once again adjusting our thought process on what causes depression. But in an effort to stave off bad advice, people telling you to stop taking your medication, and just general confusion, let’s do what we do best and talk it out. First, let’s be clear, don’t stop taking your meds, it’s never a good idea, I promise, 10 out of 10 times it’s a bad idea unless you’ve spoken with a doctor or are having serious side effects. So let’s talk about the latest news, shall we?
(more…)Conference update!


A few weeks ago I submitted an abstract to a conference that’s coming up. It’s an internally run conference that the hospital puts on every year for us to share our work with other labs. A lot of the stuff we do in the hospital is similar across labs so doing stuff like this helps everyone explore different collaborations that could be done or work that compliments other work. There’s a few things that need to happen now that I’ve been selected and there’s not a lot of time to do it, but what else is new?
(more…)The first glimpse!


Well I don’t want to say we have something… but we have something! Okay, so I guess we should back up a little bit. A few days ago we collected some data using an idea I had, my “big idea.” This was the first time we did this experiment the way I really wanted to do it, but not the first experiment, so we had a really good shot of getting some good data. Shortly after we finished the experiment I did some quick checks and we did, in fact, have data. Now the question was, what did it all mean?
(more…)Data rush


Okay well I don’t know how successful our experiment was… yet. I know we have data, which was the first hurdle, but does that data tell us anything? Will we unlock the deepest secrets of the human body (almost certainly not, but we can dream), or will we just end up with a whole lot of nothing. That’s the problem with trying something for the first time, you could have something, or you could have nothing and it’s a lot of work before you find out the answer.
(more…)Small beginnings


Sometimes big things have small beginnings. Honestly I’m not even sure how to talk about it vaguely, but I’m going to give it my best shot. The short version is that I officially have my first dataset for an idea I had almost a year ago now, a “big idea” as it were. I’m confident that this will work, I haven’t had a chance to see what we got, but I did make a few initial checks to ensure everything was collecting correctly. Unfortunately, despite how monumental this feels for me, I can’t explain what we have… yet.
(more…)New paper update


Okay, since we’re starting to wrap up the latest paper, I need to give it a nickname. I think we’ll just call it, “dual paper” since I can’t think of anything better and that is secret enough for me. Eventually I’m just going to have to start using letters of the alphabet if this keeps up. So what is dual paper you may ask? Well…
(more…)DARPA Risers 2022


Well it’s even more official! I’ve been selected as a 2022 DARPA Riser and I’ve gotten more details on the event. Today I figure it’s a good time to talk about the process as I know it and where we are in that process. Mostly because the internet had very little on the topic and because I am very excited to be part of the selection. I also now can view my fellow DARPA Risers, which has been more than just a little humbling.
(more…)Effects of transcutaneous spinal stimulation on spatiotemporal cortical activation patterns

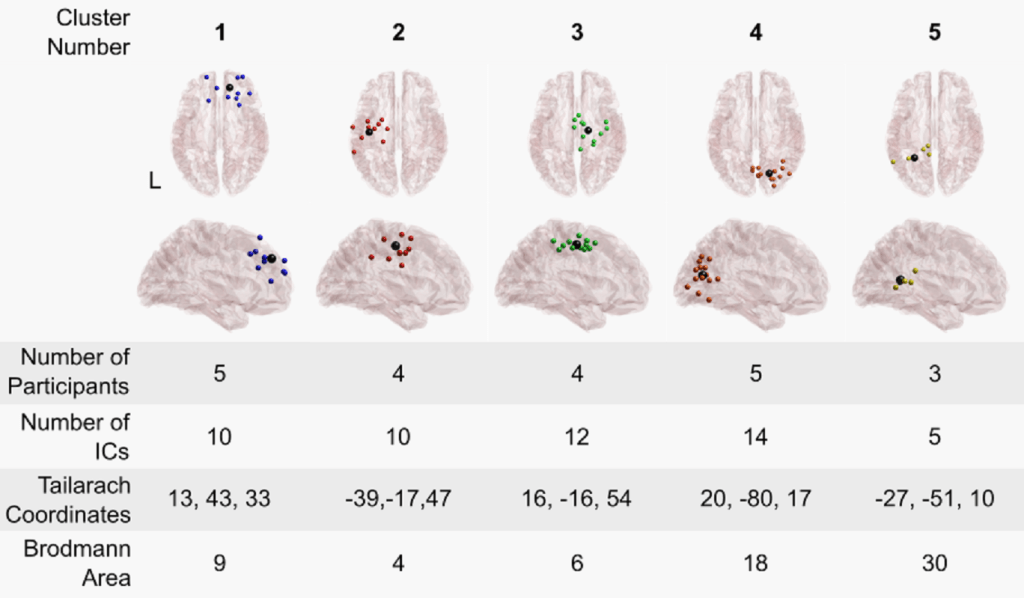
It’s official! My latest paper, what I’ve been calling “last paper” is now typeset and I can share my fancy videos better. I’m excited that this is finally here and since I gave a good overview of the paper (here) today I’ll discuss a bit more about why this paper was important and why the dataset was such a pain, both of those I had to shorten due to the length of the post.
(more…)A big breakthrough!


Okay I’m trying to remain calm because nothing is set in stone yet. However, I’m very excited because as of yesterday anyway we have the first person who is eligible for the experiment I proposed using what I call, “big idea.” Now for those of you who have been following along, this may be confusing because I already have several datasets using this new thing I’ve created, but this is a little different. Okay a lot different and I’ll explain why.
(more…)Another response letter


There’s a surprise paper I haven’t talked about much. Mostly because I’m “only” second author on it, but also because as I keep mentioning things are hectic. However, we’re almost a full six months into the year and I currently have three papers (two first author, one second author) to my name and this will be number four! It’s been a good year for me, but we’re not done yet! Today I’m going to once again talk about response letters.
(more…)Summer experiments


With summer here in pretty much full swing, we are about to get started on a bunch of new experiments. There’s a lot of things coming that will make life slightly harder, so in an effort to keep track of my progress between now and the big graduation day (soon… hopefully), let’s look at what I’ve got going on this summer. Things I need to do, things I “get” to do, and things that I can pawn off on others to do *wink.*
(more…)The hard road


Is doing something an easier way necessarily worse than doing it a hard way? I mean with a lot of things in life you get out what you put in. If you work hard enough you could be an olympic athlete, a world class musician, dancer, artist. But even in those cases, is it hard work, or consistant work that makes the difference? I’m not sure one way or the other, but I’ve typically opted for the hard way. It’s lead to mixed results, but typically I don’t mind putting in the extra effort if it means that I will have a good outcome.
(more…)Effects of transcutaneous spinal cord stimulation on the brain

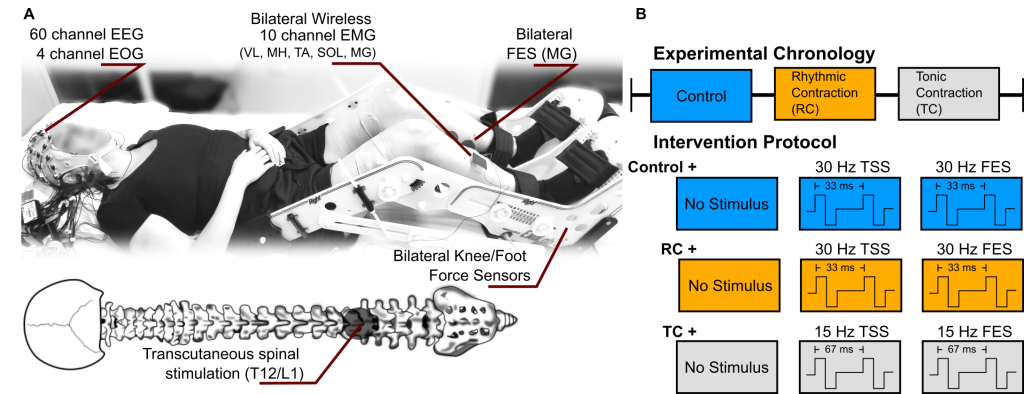
Transcutaneous spinal stimulation (TSS) is a relatively new approach to neuromodulation. We can activate networks in the spinal cord by injecting a small amount of current through the skin, which evokes a response in the muscles (muscle contraction). Depending on the person the electrical stimulus (the zappy time) feels either like a massage or it can be uncomfortable, not exactly painful, just not something you would go out of your way for. But the spinal cord is a two way street, so what does TSS do in the brain?
(more…)Data mountain


Well the week is over and I’ve barely been able to drag myself out of bed it’s been so exhausting. Unfortunately, we’re doing it all again next week too, so it’s not over yet. But the first of two test experiments are done, I say test because these don’t actually count toward our original set of experiments we’re doing later this summer. Meaning there’s going to be a lot of work coming my way, fun times.
(more…)

