Sometimes you just want to kick a distribution right in the mean.
Variance, it’s one of those concepts that get’s explained briefly then you find yourself using it over and over. Now that I have a free moment, I figure it’s about time to revisit the “simple” concept and just take a minute to apricate why we have to deal with variance so often and why we try so hard to minimize it when we’re doing experiments. Just like the discussion about the mean, there’s some subtilty that goes into the idea of variance and it’s square root cousin standard deviation and we skip over it in favor of getting into more complex topics.
Maybe we shouldn’t phrase it this way, since there is still quite a few days left of 365DoA, but you made it to the end! No, not THE end, but if you’ve been following along the past few posts we’ve introduced several seemingly disparate concepts and said, “don’t worry they are related,” without telling you how. Well today, like a magician showing you how to pull a rabbit from a hat, let’s connect the dots and explain why we introduced all those concepts!*
You have all been really patient with seeing how we tie these last few posts together and frankly I think that we are on track to do that in the next post. Today however we have one more thing to introduce then we can bring it all together, that would be yet another normal (again we usually refer to this as the gaussian) distribution. If you recall I hinted at this a few days ago in the Poisson pdf post. Let’s look at what this means and why we would want to use this.*
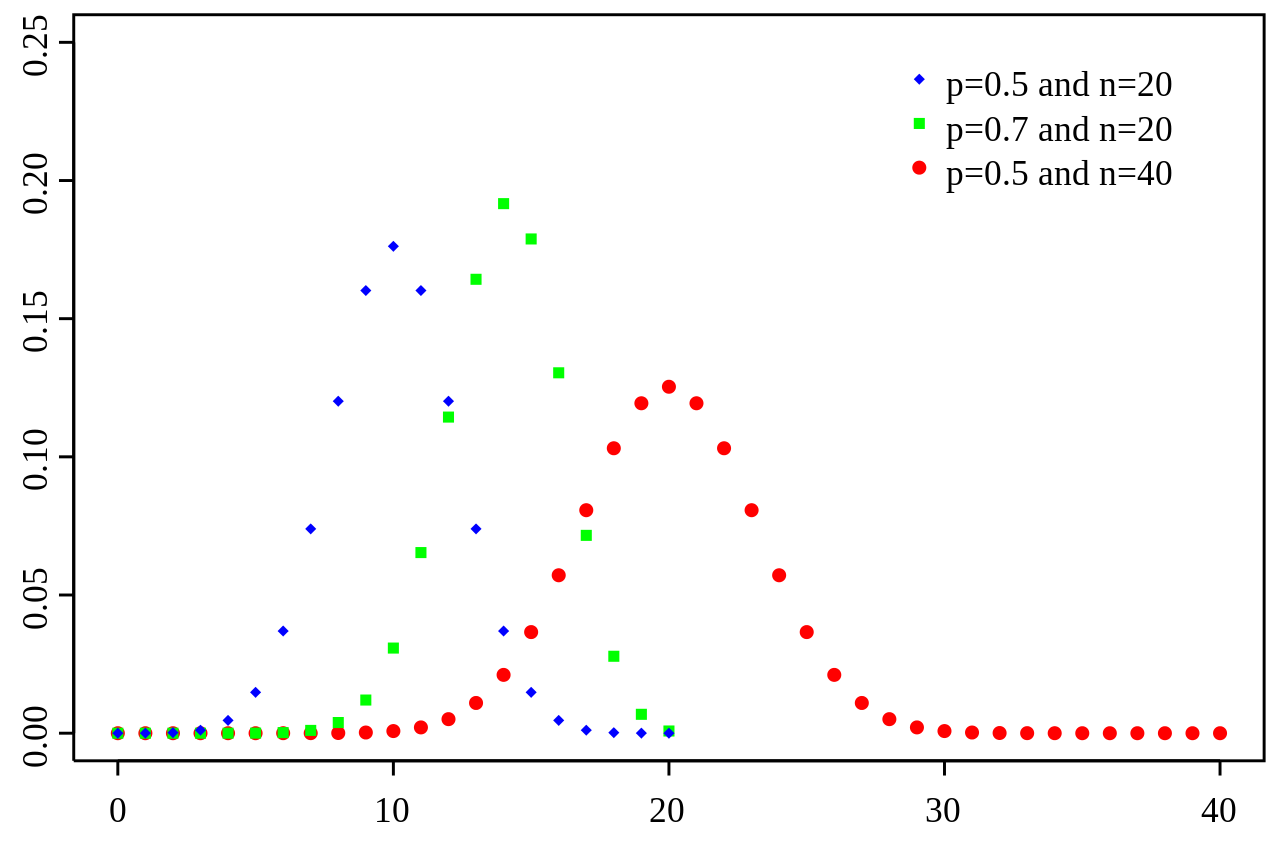
The binomial distribution, don’t worry we’ll get into it.
Well we haven’t covered the binomial distribution, but it should be vaguely familiar if you’ve been keeping up, specifically if you’ve already read about the gaussian pdf. Today we are going to talk about what the binomial distribution is and how it relates to the normal distribution. So let’s get into it and see how it relates to some of the topics we’ve been covering!*
The gaussian (or normal) distribution demonstrated by plinko.
Well what a fun day it is! Today we are going to dive into some examples (or maybe just an example) of the gaussian (also known as the normal) distribution. Last post we looked at the laplace distribution and discovered there aren’t a whole lot of uses for it because it is technically a special case of the exponential distribution. This isn’t the case with the gaussian, there are lots of really interesting things we can model using the distribution that are applicable to everyday life, so let’s get started!*
Now it seems like we are getting somewhere. Last post we covered z-score and you can read that if you haven’t already, it might be good to familiarize yourself with it since today we are going to talk p-value and the difference between z-score and p-value. That said, let’s dive in and look at the value in the p-value.*
So if you recall from last post… well I’m not linking to it. It was hellishly personal and frankly I’m still attempting to recover from it. We’re going to take it light this time and we can do a deep dive into something in another post. For that reason, let’s talk about z-score and what exactly it is, I mean we used it in this post and never defined it formally, so let’s do that. Let’s talk z-score!*
Technically we could call this parametric statistics part 2. However, since we are covering nonparametric statistics and more importantly the difference between parametric and nonparametric statistics, it would seem that this title makes more sense. As usual with a continuation, you probably want to start at the beginning where we define parametric statistics. Ready to get started?*
It’s halloween time, we are talking about normally distributed data, so this fits, and I don’t want to hear otherwise!
Well my lovely readers, we’ve made it to the three week mark, 5.7% of the way through! Okay maybe that doesn’t seem like a big deal written like that, but hey it’s progress. So last post we had our independence day, or rather defined what it meant to have independent events vs. dependent events. We also said it was an important assumption in parametric statistics that our events are independent, but then we realized we never defined what parametric statistics even is, oops. So let’s stop dragging our feet and talk parametric statistics!*