Day 35: Example of the Gaussian pdf

The gaussian (or normal) distribution demonstrated by plinko.
So we’ve covered a exponential distribution example and we’ve covered the laplace distribution example. We’ve also covered the math behind the exponential, laplace, and the gaussian. Technically we’ve even done an example of the gaussian, but there are so many different uses we can do another example today just so we have everything in a semi-ordered manner. Okay, refresher time and my reminder that if this is new to you, you should start from the beginning which is roughly this post where we introduced the concept of the pdf and CDF. If you don’t recall what our gaussian distribution looks like, it looks something like this guy:
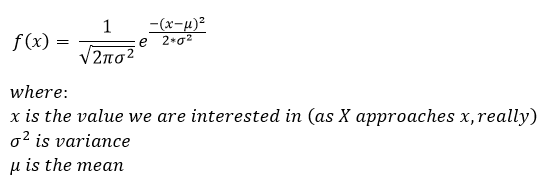
Then we derived the CDF from this and it ended up looking something like this:

Of course this was when we were still just introducing the concept of the pdf and CDF so we took a step back and created our own pdf to use as a demonstration. This is because, well look at the CDF for the normal distribution, it isn’t very intuitive, specifically with the error function (erf) hanging out in there. Now, we never covered it, but the erf function written out looks like this guy:

HOWEVER, and this is a big however, note that there are many ways of writing the error function and some derivations use something called the incomplete gamma function (which we may cover eventually), some approximate it by using a Maclaurin series (a version of the Taylor series), and some use the erfc (do NOT confuse this with the erf), erfc is the complementary error function and we will most definitely be covering the idea of something being complementary in an upcoming post. The basic idea is that the complementary error function is everything that the error function is not, so naturally the equation is just:
1-erf(x)
That covers most of the stuff going on under the hood of the gaussian pdf. It also explains why when dealing with the gaussian there are look up tables for values. Yep, still to this day we use them. That’s just because there isn’t a gaussian distribution button on (most?) calculators… yet. So let’s look at another example and see if we can put this all together.
Let’s say that the length of time between charging your cell phone battery is normally distributed with a mean of 18 hours and a standard deviation of 8 hours. Now, you are going on a business trip and want to figure out if you should pack your charger (the answer is of course yes, always, but what are the odds you need it?). You plan on being on this trip and potentially away from your charger for between 16 and 26 hours. What is the probability that your battery will make the trip without a charge?
First, for most of us (myself included this is more of a horror movie then a statistics problem, but it is a very good real world example (-ish, we assume a gaussian distribution, it doesn’t have to be and in fact, it may not be). Okay, so now we have some math we can do. We know our mean and our standard deviation, so we can determine our variance by squaring the standard deviation.
Now, let’s say our x is the random variable that represents the length of time. The mean is 15 and standard deviation 8, and the question we want to answer written more formally is this:
P(16<x<26)
Now, because we are going to use the lookup tables to find our values under the curve, we need to determine the z-score, you may remember z-score from this post. We said that z-score is calculated by:
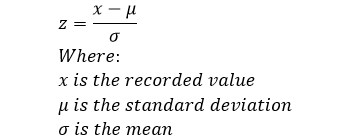
So let’s plug in our values and see what we have:
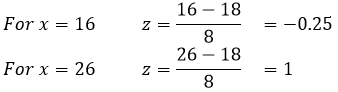
We can now ask the question in terms of our z-score, such that:
P(16<x<26) = P(-0.25 < z < 1)
Now we can use our handy z-score table to find our values, notice that I’ve already highlighted them for us so you can see how the z-score table works. We can go into more detail about how to use the z-score table some other time if there is any confusion.

You can open the table in a new window to see it full size, but I’ve highlighted the two scores we are interested in, notice that one is negative, so we had to use the negative z-score table and the positive z-score table. We find that P(z = -0.25) = 0.4013 and P(z = 1) = 0.8413. Further notice that we were interested in the area to the left of the z-score because we are dealing with everything prior to that value (IE we are going from -∞ to x not +∞ to x. Okay, so we have our z-score values, now what?
What we now know is how much area under the curve is encompassed by going from -∞ to x, where x is our bounds, but if we use just one value that would be the probability that the phone would last from -∞ to x (where we could select x to be 16 or 26 hours. That wasn’t what we wanted to know, we want to know what the odds are the phone will last between 16 and 26 hours, so we need to subtract our values such that:
P(16<x<26) = P(-0.25 < z < 1) = [area to left of z = 1] – [area to left of z=-0.25]
= 0.8413 – 0.4013 = 0.44
So using our approximation, we have determined that the odds your phone will make the entire trip without needing to be charged are 44%. In other words, it might be smart to carry your charger!
Okay, now why did we subtract our values? Well we were interested in a section of our curve so we need to take our upper value (which includes everything from -∞ to that point) and remove the lower value (which includes everything from -∞ to that value and what we are left with is the section of interest. I’ve (terribly) illustrated the bit we are interested in here:
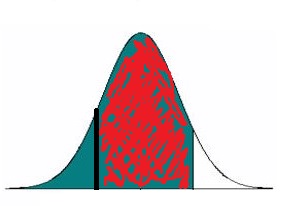
Where the dark line on the left is our lower value and the end of the red shaded area (where it becomes white) is our upper value. Yes I probably could have made a better graphic to illustrate this, but I think you get the point and these posts take some time to write without trying to get fancy with the graphics.
In any case, that covers the three types of distributions we’ve talked about, next I think we will talk about a new type of distribution, it’s a simple one, so don’t worry the math will be pretty straight forward. Or we could cover something different, I haven’t decided yet. In any case, you’ll have to stay tuned to see what is up next.
Until next time, don’t stop learning!
*My dear readers, please remember that I make no claim to the accuracy of this information; some of it might be wrong. I’m learning, which is why I’m writing these posts and if you’re reading this then I am assuming you are trying to learn too. My plea to you is this, if you see something that is not correct, or if you want to expand on something, do it. Let’s learn together!!



Picture after “Then we derived the CDF from this and it ended up looking something like this:” is a BS. You have a definite integral with respect to x, it can not depend on x.
LikeLike
March 5, 2021 at 11:24 am
Well I’m slightly confused by your comment, maybe it’s the way you worded it. I believe you mean to say that my limits are wrong and you are correct. It looks like you’re the first person to point that out, I’ll take care of it when I have a chance, not today since I’ve got a lot going on. Solving it the way it is now would give you 1, when really it should be -inf to x not +inf (or x to +inf I guess if you were coming at it from the other direction). Nice catch!
LikeLike
March 5, 2021 at 3:33 pm