Day 27: Probability density functions, Part 2
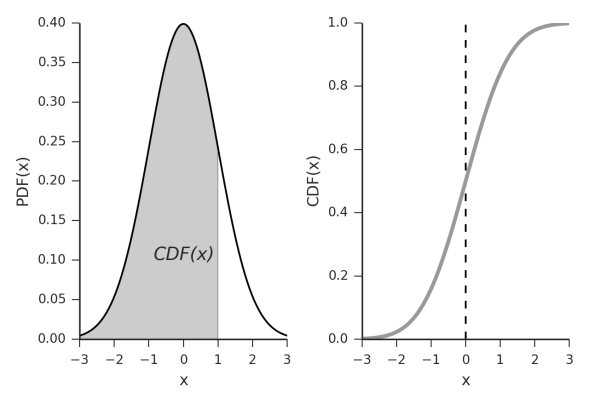
Today we are looking at our p.d.f. (yes this image has p.d.f. written as PDF, please don’t be confused!) and our C.D.F.’s let’s do this!
Oh hi didn’t see you there. Today is part 2 of the probability density functions notes (posts?), whatever we are calling these. You can read part 1 here as you should probably be familiar with the (super confusing) notation we use to describe our p.d.f. and our C.D.F. now that we’ve given that lovely disclaimer, let’s look once again at probability density functions!*
Picking up right in the thick of things, we said we have a p.d.f. and the big brother our P.D.F. which we are calling our C.D.F. Now we said our p.d.f. stands for the probability density function, while our capital P.D.F is our probability distribution function also called our cumulative distribution function which we suggested to save us the trouble of distinguishing the p.d.f. and P.D.F. with a disclaimer, we would just refer to the P.D.F. as the C.D.F. and hope that you can keep the two seperate in your heads with that distinction.
We also made a note that our C.D.F is just the integral of our p.d.f. (making the p.d.f. and P.D.F. notation even more confusing in my opinion). We can talk integration later, but it is a math concept that you might want to brush up on, on your own if we deep dive into this. We also said that the probability that we would find a specific value on our p.d.f. when dealing with a continuous variable was zero! That didn’t stop us from reframing the question though, we said we could use the p.d.f. to determine the probability that a value will fall within a range of values, which was really the question we’ve been asking from the start.
One more thing before we dive into this some more. First, we are talking continuous variables, think of continuous variables as analog inputs they can take on any value from 2 to 2.435987345873485. There are cases where we deal with discrete variables, but that is a different case which we will look at separately. Discrete variables take on set values like digital inputs, if we think back to our coin flipping experiment, we were dealing with a discrete variable, the value could only take on heads or tails, failure or success. Not so with continuous variables so the math is different. Because I have a calculus background as an engineer talking about our continuous variables will be easier since derivatives and integrals make the math simpler (caveat: only if you know those concepts). We will be talking continuous variables first for this reason, but don’t worry, we will talk discrete too.
Okay, so let’s look at a specific example. The normal distribution! Our (by now) old friend is also known as the Gaussian distribution and is the most used statistical distribution because there are so many physical, biological, and even social processes that it models (how cool, right?!). The formula for the probability density function (p.d.f.) is going to be the (somewhat scary looking):
 This makes for a nasty integration when going to the C.D.F. but fear not! It’s already been solved and you (probably) won’t have to deal with deriving it yourself unless you are bored or taking a class on the topic… oh wait that’s me… In any case, the plot of that function looks exactly like this very familiar looking plot
This makes for a nasty integration when going to the C.D.F. but fear not! It’s already been solved and you (probably) won’t have to deal with deriving it yourself unless you are bored or taking a class on the topic… oh wait that’s me… In any case, the plot of that function looks exactly like this very familiar looking plot

If you are really bored you can actually prove that the area under the curve is 1. Normally when you see something like this it will be written in this format, N(μ,σ) and that’s it. That’s really all you need to know to calculate the p.d.f. but let’s look a little closer.
The N as you may have already determined means normal distribution so we know right off the bat what the equation looks like. Next we see all we need to know to describe the entire p.d.f. is the mean (μ) and the standard deviation (σ). However, this assumes a priori knowledge about the p.d.f distribution. When we say a priori we mean knowledge before the fact, or what we assume to be true from experience. There are a posteriori ways to do this too. Which you may have guessed using your a priori knowledge, but that means knowledge after the fact, or running an experiment and looking at the data to determine something about the model. We can dig into that some other time though since that is taking us off topic a bit.
Okay, you may have noticed that when I posted the function there was a note to our x variable. It wasn’t written, but it should look more like this:
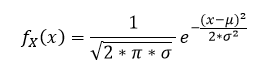 However, we didn’t write that out because it’s confusing! Well to me anyway. What this says is that, the probability distribution function for the random variable X, evaluated when X is x, or rather when X = x. Let’s look at a simple example that doesn’t use the p.d.f. from our nightmares.
However, we didn’t write that out because it’s confusing! Well to me anyway. What this says is that, the probability distribution function for the random variable X, evaluated when X is x, or rather when X = x. Let’s look at a simple example that doesn’t use the p.d.f. from our nightmares.
Say that X has a range from 0 to 1 and on that range the p.d.f. is 2x. This means that it is very unlikely that x will be near zero, where the p.d.f. is very small so the values will most likely be near 1. In that case we can say that:
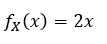 We can use our C.D.F. to determine the probability of ending up with say X ≤ 0.5. First, what does our C.D.F. notation look like, well you would typically see it written like this:
We can use our C.D.F. to determine the probability of ending up with say X ≤ 0.5. First, what does our C.D.F. notation look like, well you would typically see it written like this:
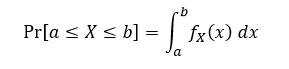 Next we just plug in our function into the equation which is:
Next we just plug in our function into the equation which is:
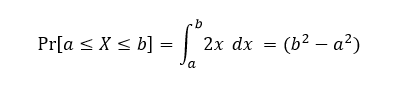 Now again, if you are confused at this point because you don’t know integrals, then now would be a good time to watch a tutorial on them. This example was selected because the integration is simple so a quick youtube video on them should help at least see why 2x comes out the way it does when we integrated it from a to b. Here is a great series on calculus by 3Blue1Brown and it covers derivatives, integrals and all sorts of other things that you might want to learn. Don’t worry, I’ll be here when you get back…
Now again, if you are confused at this point because you don’t know integrals, then now would be a good time to watch a tutorial on them. This example was selected because the integration is simple so a quick youtube video on them should help at least see why 2x comes out the way it does when we integrated it from a to b. Here is a great series on calculus by 3Blue1Brown and it covers derivatives, integrals and all sorts of other things that you might want to learn. Don’t worry, I’ll be here when you get back…
So now we’ve solved our C.D.F. and we are all set to plug in some values. We wanted to see what the probability of our value x as X = x is when X ≤ 0.5. Well to do that we just plug our values into the equation for a and b. Remember this is from a to b so in our case b is the value we end at (IE 0.5 since we said less than or equal to), but what is a? a is just the minimum value that our function is valid for, which we said is 0. Just remember, this is only the case for our example, when you are doing this with your p.d.f. the values might be different. For example your p.d.f. might be valid from -∞ to +∞. In that case if you’re interested in the probability that X ≤ 0.5, your b would be -∞ and not zero. So let’s plug in the values and see what we get:
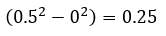
From this you can see that as we get closer to 1 the probability that we find our value in that range increases. Furthermore, you may have noticed, but if we plug in our limits we see that finding the value 0 ≤ X ≤ 1, we get
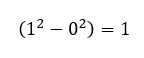
This should be comforting because we know that the probability that we will find our value between 0 and 1 needs to be 100%, in this case it is! Also as a side note, remember that we don’t always have to evaluate (even in this example) between b and a=0, we could’ve asked what the probability was that our value was between 1 and 0.5 for example which would give us a probability of 0.75 or 75%, I could show you how I got that, but I’ll leave it for you my dear readers to figure out, just plug in the values for a and b!
Well with that I think this is a good place to stop. We will do a more exhaustive dive into the normal distribution p.d.f. next I think. However, it was important to open with a simple example to demonstrate how the two concepts p.d.f. and C.D.F. are related.
Until next time, don’t stop learning!
*My amazing readers, please remember that I make no claim to the accuracy of this information; some of it might be wrong. I’m learning, which is why I’m writing these posts and if you’re reading this then I am assuming you are trying to learn too. My plea to you is this, if you see something that is not correct, or if you want to expand on something, do it. Let’s learn together!!



But enough about us, what about you?