Real-time seizure state tracking
Since I shared one of the papers I was super proud of, I figure I can share the other one as well. Like the last paper (here) I’ll explain the concept and why this paper was important. I’ll also talk about why I think it was cool and where the idea came from. Mostly this post is for people who are interested in the work, but may not be familiar with the technical aspects so I’ll try to avoid technical terms or I will provide an explanation when needed.
The first line in the introduction of the paper sums up the problem very nicely. It’s estimated that roughly 50 million people live with epilepsy worldwide. That’s a big number and unfortunately treatments for epilepsy are limited. You have several things in play here, but there are medications, surgeries, and even neuromodulation approaches for treatment. Neuromodulation uses electrical signals to help fix whatever is going on, think of it as a pacemaker for a nerve or even the brain. The problem is that most people won’t find full relief from medication and surgeries to fix the issue usually involve removing the portion of the brain causing the seizure, so high risk.
Neuromodulation is a great option, but it’s not without side effects. Because most of the options are open-loop, meaning always running no matter what’s going, the person receives treatment when it’s not really needed. Ideally we would “close the loop” and you would have some sort of feedback system to let the neuromodulation device know when to run and when to shut off. This is easier said than done because there’s not a whole lot of visible warning and the person who is experiencing the seizure may not even know it’s about to happen. So what’s a good way of monitoring for a seizure?
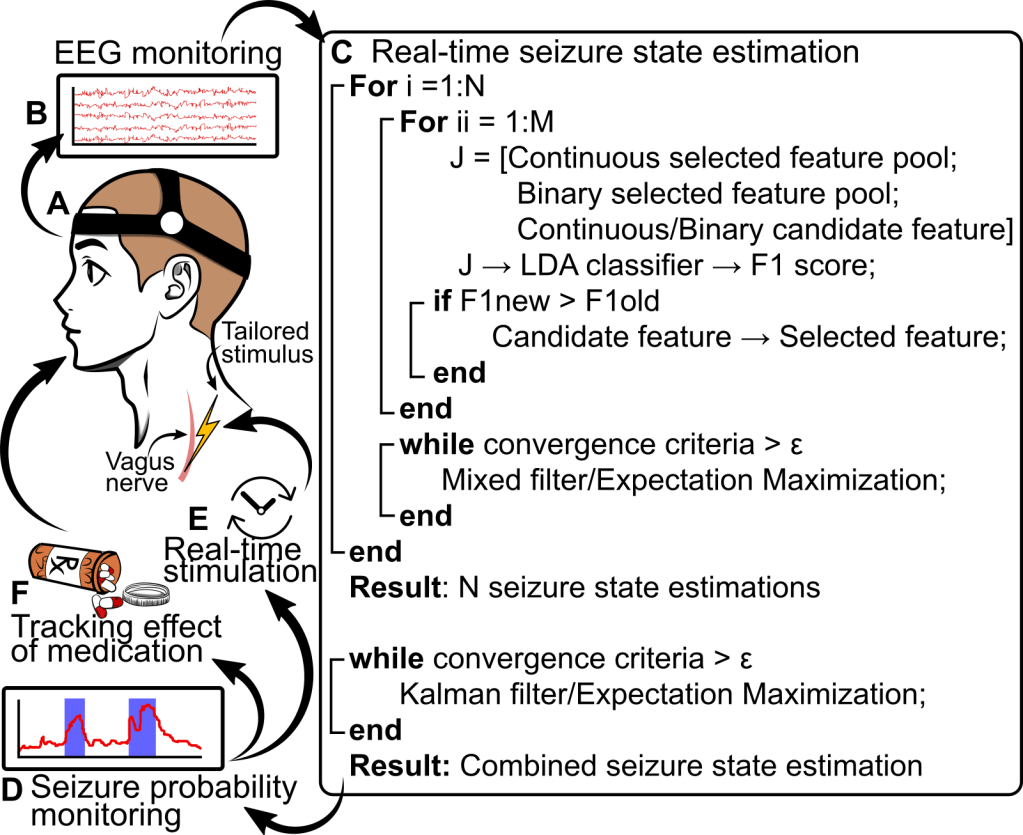
For the past four years or so now I’ve been working with EEG (electroencephalography, which is a mouthful!) which is a non-invasive way to measure brain activity. We can’t read your mind, but we can, to a certain degree of accuracy, predict when you want to move, when you’re concentrating, and a whole lot of other stuff. If you want to learn more about EEG by the way, I wrote a whole post breaking it down a bit (here). Since EEG is non-invasive it’s safe to use by just about anyone (even babies). This work uses EEG to predict if the person is having a seizure or not and we do it in a real-time applicable way.
Again, easier said than done because we have brain activity, but we don’t have an easy way for a computer to decide if that activity is seizure related, regular brain activity, or if it’s due to motion artifacts or other noise sources. Side note, EEG is very sensitive and we record on the order of microvolts, any movement of the electrode relative to the scalp will cause artifacts, so will EMG (muscle activity) or just being around electrical equipment. We can literally pickup the 60 Hz (USA) line noise from the electrical cables running in walls, it’s wild. To help deal with this issue, our method uses a multiple sensor state space approach with a Kalman filter (so much for not using technical terms!), but don’t worry I’ll break that down.
Think of state-space modeling as predicting the state of something, the state-space in state-space modeling is the “space” of all those states. A lightswitch for example can be on or off, so it has two states. The easy way to tell if a lightswitch is on is to look at it, think of that light switch as the true seizure state, either the person is having a seizure or they are not. Unfortunately we can’t see the light switch, we can only montor the light in the room and predict if the switch is on or off based on those values. To make matters more complicated sticking with our metaphor, the room has windows so sunlight is a factor. Tricky, tricky, right?
So we “train” or model. We give it example data that we know for sure has the light switch on and example data with the light switch off. In our paper’s case the recordings we used were marked by experts to tell us when a person was experiencing a seizure, so we knew the state of the light switch so to speak. What makes our paper special is we don’t just do this once, we use several different sensors that have the most predictive power (think of it as finding the sensors that are away from the windows and closest to the lights). This gives us more stability because if one sensor is very noisy we can rely on the others to make a better prediction.
So now we have all these predictions, how do we make sense of them? That’s where the Kalman filter comes in. A Kalman filter is a special adaptive filter that takes all that data, makes a single prediction based on that data, then when the real state is known it updates how it predicts so the next prediction is more accurate. There’s not a lot of math to a kalman filter believe it or not and funny enough I already wrote about the math in detail (here).
Kalman filters are awesome because they are very computationally efficient and you can make accurate predictions with them when you have a better understanding of the underlying model. The more data you give it, in theory, the better the prediction because the filter updates at every step.
State-space models are also very computationally efficient and they can be related to the underlying biology (we can learn new things about the brain for example), but in both cases we have what’s called a continuous output instead of binary, think dimmer switch instead of regular light switch, we have any number between 0 and 1 that we can pick from, so we can use that information to get an idea of how well medication is working, other treatments, or just to monitor the person.
Since our method is computationally efficient, we aren’t limited to how we can run the software. Ideally a person could download an app to their phone, put on the sensors — via a hat or some other type of headwear — and they would be able to monitor the probability of a seizure occurring. If the system detects a seizure it could alert the person and/or activate the neuromodulation device. Better still because we have these EEG recordings and predictions a doctor could use that information to better tailor treatment for the person.
Accurate and fast detection is important because, in certain cases, applying treatment (speaking of neuromodulation in particular here) too late can make the seizure worse. Our method gave a 92.7% accuracy a 92.8% sensitivity, and a 93.4% specificity. Sensitivity is the true positive rate (we predict a seizure when a seizure is occuring) while specificity is the true negative rate (we predict no seizure when no seizure is occuring). Out of the three other groups we compare our findings against (all using the same dataset), only one group did better, but that was not real-time applicable and required a high level of computation so a computer would be required.
There wasn’t room in the paper to include this, but I actually went further and found a way to increase the accuracy by applying a low-pass filter using a method that could be applied via hardware (so no added computation required). Additionally we only used two seizures, one for training and one for testing, which sets a sort of minimum to our accuracy.
When creating a model you have a training set and a testing set (I’m probably getting the sets mixed up I do this a lot, you also have a validation set so probably best to ignore the names). The training set is what you use to create the model, but you can “overfit a model” or get 100% accuracy only with that data, so once the model is trained, the test set is used. The model hasn’t seen the test set so this gives us an idea of how well the model performs. It cycles through training and testing until a good solution is found and then we validate our model using the validation set (data the model hasn’t seen for testing or training).
In our approach we used data with one seizure for training, data with one seizure for training and the rest of the seizures for validation (per patient since this needs to be tailored to the individual). In some cases the patient data only included three seizures, so we wanted to keep it to the minimum required so we could get the most out of our validation. Here’s the great part though, in the real world you would do the same approach, train using one seizure, test using one seizure and the rest would be real-world validation. However, you could then go back and keep improving the model using the new seizure data.
Due to length limitations we don’t explore this option, but I did the extra work for the class and we found that between my low-pass filter and one extra seizure used for the training (which left us with only 4 out of the 10 patients which had > 3 seizures in the dataset, so a very small subset of the data to use) we got a 99.7% accuracy, a 99.9% sensitivity and a 99.9% specificity.
Now this is offline testing and in the real world we probably wouldn’t see that kind of accuracy, but I’m sharing this extra bit because it gives me hope that the accuracy can be easily improved with more data and that there is room for improvement.
While this paper wasn’t “the stuff I’m really excited about” it was very exciting to be first author on this research and I learned a lot doing this project. This paper (in my opinion) holds a lot of hope in helping people who live with not very well controlled seizure activity. I’m proud of the work we did and as we discuss in the paper, the work from the previous team whose work we built upon here.
The paper goes into a lot more detail about what we did and how we did it, but I hope that this explanation makes the paper more accessible to a general audience.
Source:
A. G. Steele et al., “A Mixed Filtering Approach for Real-Time Seizure State Tracking Using Multi-Channel Electroencephalography Data,” in IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 29, pp. 2037-2045, 2021, doi: 10.1109/TNSRE.2021.3113888.
Oh and since I’m outing myself, the work was featured by my school:
Biomed, ECE, McGovern Collaboration Leads To New Epilepsy Research
The senior author (Dr. Faghih) is probably the most brilliant person I’ve ever met, so I’ve been very lucky to learn from her. I talk a lot about her because she had the kind intelligence and ability I want, but I think people are born like that, so I’m probably out of luck. Not downing myself, but more like acknowledging I’m about average and she certainly is not. She was named one of MIT’s top 30 under 30, so if anything I’m underselling her abilities, in the article and in general. If you can’t tell, I really do look up to her.



Very interesting and thank you for choosing this field. I have seizures that are complex, as I may stare of into space, or slur my words during an episode, or my head might feel as though it is going to explode as my heart beats wildly and then there is the eyes rolling to the back of my head as I drop little a lead weight to the ground. (The fainting ones are getting more frequent.) They are all scary, especially never knowing if this time it’s the ONE. I am always hoping for new and better treatments as medication does nothing for these types as I have heard from a few neurologists and even a neurosurgeon. Keep doing your thing as you may be the one to crack the code on seizures! (By the way, I think this is why I happened upon your blog.)
LikeLiked by 1 person
January 6, 2022 at 10:57 am
Ugh, I’m sorry to hear that! It’s cases like yours that made me excited about this paper. Neuromodulation has promise in treating hard to treat seizures, but it’s still in the early stages so there’s a lot of room for improvement.
LikeLiked by 1 person
January 7, 2022 at 9:10 am