The f-test in statistics

Yep, we’re getting right back into it. I’m still working out things from yesterday, so we can just talk more statistics. This will be an interesting one and hopefully it will be pretty straightforward. The f-test, which in this case is really the f-test to compare two variances. You may have guessed, but the t-test uses the t-distribution (sort of like the normal), well the f-test uses the f-distribution, which is nothing like the normal! Let’s dive in, shall we?
Statistics can be so mean! Okay, that wasn’t a great joke I admit it, it was pretty… normal. But seriously, the “in statistics” series is meant to help me you understand some of the more complicated things about statistics. I’m the kind of person who needs to understand the “why” behind things. Like why does it matter that we have two distributions with the same (or close) variance when we do these tests?! This is part explanation of the things I’m learning in my class and part details that are normally glossed over. If you’re like me and need to grasp statistics, but don’t understand how any of it works, well then this is for you.
The f-test (to compare two variances) is just what the name sounds like. We’re using the f-distribution, which looks nothing like the t-distribution or the normal distribution, to determine if our variances are similar enough that the “must have equal variances” tenet holds true, because in reality they don’t need to be equal, just close. How close? Well that’s what we can use the f-test to find out.
Just like the t-test we need to determine our alpha (or significance value). Normally we set it at 5% or 0.05, but not always (read more). The f-test and t-test don’t just use different distributions, they look at different things. We mentioned the f-test looks at variance, while the t-test looks at mean. So we use the t-test to determine if our mean is significantly different from another sample. We use the f-test when we want to check if our variances are similar enough to be considered the same or if they are different.
Typically we use the f-test before we run the t-test to make sure our assumption that the variances are equal holds. That makes the f-test super important in cases where we’re not sure if that’s the case. Unlike the t-test however, we want the null hypothesis to hold. Which is to say, we want our two samples to be similar. So the null hypothesis is that our variances are the same, our alternate hypothesis is that they are different. With a confidence of 0.05 we want the critical f-value to be below whatever our 0.05 value is. Let’s look at an example of the f-distribution, below is an image showing how it changes as our degrees of freedom (n-1) increase.

Notice how we have 2 degrees of freedom, df1 is from one sample, df2 is from the other. As you can see we don’t need our samples (remember our samples are the two groups we’re comparing, not one data point, which for me was easy to confuse) to be equal for this to work, but it helps to have more data (ain the general sense). We’ll discuss how this is used in a minute, but first let’s look at our f-test. The equation to determine our F value is pretty easy to understand its just:
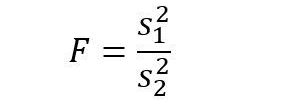
Which is just the ratio of our variances, variance of sample 1 over the variance of sample 2. If our variances are perfectly equal this returns a value of 1 (10/10 = 1 for example). So our null hypothesis is that the F = 1 or that the variances are equal, that will be the case ALWAYS. Because the shape of our distribution relies on the degrees of freedom, we don’t normally find our significance values by hand. Instead we either use software (R, g*power, MATLAB, etc) or we have our handy tables! For that we can make a quick example so we can use our table to find our solution.
Let’s say we want to determine if our variance of one sample is significantly larger than the variance of our second sample. We want our normal confidence of 5%, but since this is a single tailed test (the right tail) we can use a single tailed table with all 5% in that tail. Normally tables will tell you if they are single tailed (left or right if the distribution is asymmetric) or if they are two-tailed, so no tricks there, you just need to find where it tells you that information which isn’t always as obvious as you would like. Now say we have 16 data points for each sample, or a df1 = df2 = 16-1 = 15 situation. Next, let’s say our F = 2.1, that seems already to tell us that our sample 1 variance is over twice the size of sample 2, but is it significant!? Let’s find out, to use a f-table you look at the degrees of freedom for your first sample, follow it down until you get your degrees of freedom for your second sample, and you have your value (this assumes you selected the correct table of course) I’ve highlighted the two columns so we can find our solution easily. This is a shortened table, but there are longer versions if you want to go old school and look this up manually.

The red highlights show you how to select your column and row, it may have been better to use two different degrees of freedom, but for this table we have a one tailed (right) test with our alpha set to 0.05 (shown in the picture above the table itself). The columns are the degrees of freedom (df) of our first sample, and the rows are the df of our second sample. The intersection (highlighted in orange) is our value and is 2.4034, so we cannot reject the null hypothesis and conclude that our variances are equal.
We didn’t mention it, but which variance is the top value and which is the bottom? Well the convention is that our sample with the larger variance is sample 1, because our variances will always be positive, or value will always be positive and will always be greater than or equal to one. You can sometimes get something slightly smaller than one when you use software, but that’s just because of rounding errors and what not, but that’s extremely rare. If you calculate by hand you can get something smaller than 1 if you put the lower variance value on top by mistake, so be careful with that.
Once you know your variances are similar you can go calculate your t-test (assuming you want to go that route). The f-test has other uses, like regression analysis, or a post-hoc ANOVA test, which we may or may not cover the first, but we’ll talk ANOVA soon. As usual, the f-test assumes your distributions are normal and the data are independent. Keep in mind that your variance is standard deviation squared, so if you have standard deviation you can still use the f-test. Lastly (talked about here) if your using a 2 tailed test, you need to divide your alpha by 2 because if your alpha (critical value) is 5% error, you want 2.5% error in each tail for a total of 5%. You do not need to divide if you’re only using a 1 tailed test.



getting a lil punny there…sorry just being average…
Anyhow, this reminds me of Mr. Pleasan (?) my Intro Physics teacher in college and our first day of class. He was explaining reaction or cause and effects (the weed) by throwing a tennis ball against the back of the lecture hall…it was one of my favorite classes.
Thanks for your great lessons 🙂
LikeLiked by 1 person
March 11, 2021 at 12:22 pm
Haha! Thank you! I’m glad my post reminded you of your favorite class, that’s a good sign for me.
LikeLike
March 12, 2021 at 9:21 am