The third lecture!?

It’s time! Okay not quite, but very soon! It’s time for the last of my summer lectures for the interns and I’m excited to wrap this up and focus on other work. There’s a lot going on so maybe first we’ll talk about how my schedule conflict shaped up, what I’ll be teaching, and why I love this class so much. I’ve been debating about making a seperate post to share the knowledge. Since I did that last year, with the classes I’m teaching this year, I don’t know if it makes sense. Maybe a review would be in order anyway…
This week has been a struggle! On one hand we’ve been swamped at work. I have new sets of experiments happening, I’ve had three experiments, two papers, 🎵 and a partridge in pear tree 🎵 (aka a grant proposal). But seriously, it’s been busy and I only had most of last week to recover, but whatever, the next few weeks are shaping up to be better. In the end the experiment I thought was going to conflict with my lecture now only conflicts with my class, but I miss class a lot (it’s more of a school-PI lab meeting) so that is actually not an issue). Yay for things working out!
Did I get extremely lucky, you bet I did!
Okay, now onto the class I’m teaching. It’s one of my favorites because it’s so cool and the math is surprisingly easy to understand from a high level (as long as you squint really hard). The class is on independent component analysis (ICA), specifically for EEG. A while ago I posted about “last paper,” which was recently published (this guy!) and I used ICA to cluster my dipoles (common areas of activation) to do the analysis and basically lived in “IC space” meaning I used the IC’s (independent components) for analysis instead of the mixed signals from the sensors. After literally years of working with the data, I’m convinced this is a better way to do analysis for the most part, but specifically for my case.
So that’s the class I’m teaching, specifically how ICA works, what you can do with it, why we use it, etc. There’s a whole lot of information out there, but I’ve written a few times on this (here and here for example). What ICA does is separates out independent signals. Independence is a very rigid math term, but for our purposes we can talk about it using an example.
Imagine you’re at the superbowl! For those of you who don’t know what that is, it’s an American football championship and it’s a big deal here in the US. Think thousands upon thousands of people crammed into a stadium, but you’re not one of them! No, you’re out in the parking lot. You can think of EEG (non-invasive way to record signals from the brain by placing electrodes on the scalp) as microphones and you have a ton of them all surrounding the outside of the stadium. What ICA does is lets you separate the individual signals or common areas of activation.
Now you can’t hear a single person talking inside the stadium, that would be impossible with our current technology, BUT we can hear groups of people shouting together (think cheering) and we can seperate that out from other people cheering for the other team for example. This is a good way to think of EEG because we can’t “hear” a single neuron in the brain firing, but we can “hear” groups of them firing (cheering) together. But because they get jumbled together with other groups firing we end up with a mix of signals.
ICA takes those mixed signals and separates them so we have (mostly) individual groups of common noise (common firing in the brain, or common cheering in our example). There’s a bit of math involved, but it’s like three major steps. The weighting matrix is a way to find independent components and I like to think of it as rotating our axes (since we’re working in high dimensional space this is hard to imagine) until we have minimized the variance for that axis (maximizing something called kurtosis), but this is probably taking it too far for this post.
Think of the weighting matrix as a measure of how far away the conversation (cheering) is away from our microphones. Some will be closer to the side with the cheering and others will be further away, the weighting matrix ![]() gives us that measure. By multiplying that with our raw data (x) we get the individual components (IC activations or a), so really it’s multiplication (see below) and because it’s multiplication we can go both ways to IC space and back to “sensor space” by multiplying by the inverse.
gives us that measure. By multiplying that with our raw data (x) we get the individual components (IC activations or a), so really it’s multiplication (see below) and because it’s multiplication we can go both ways to IC space and back to “sensor space” by multiplying by the inverse.
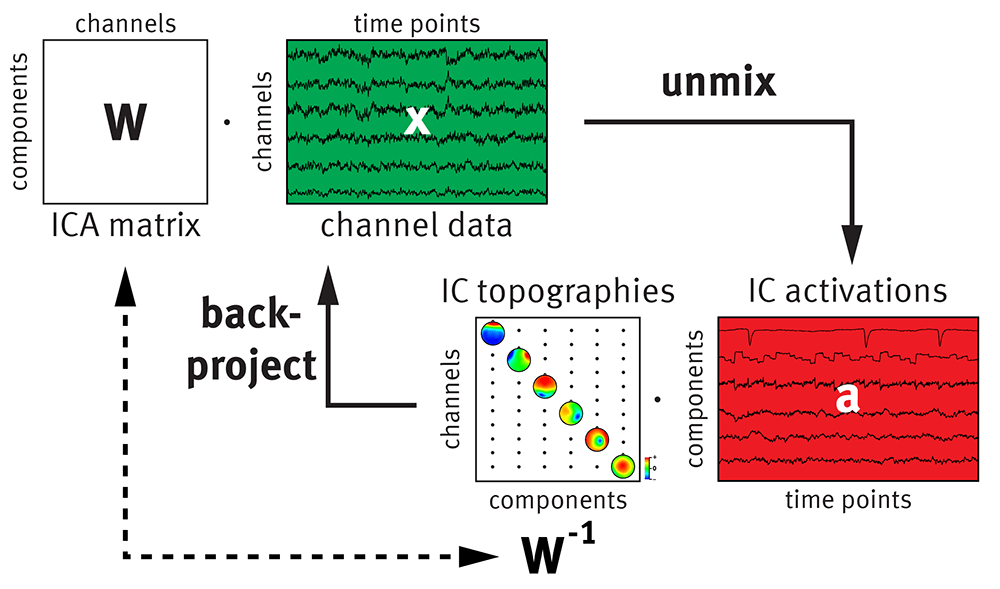
That ability means we can filter out unwanted “cheering” in our case that would be random noise we pick up with our “microphones.” Then we can go back to sensor space (channel data) with that bit of information removed, or we can live in that IC space and do all sorts of fun things there depending on the questions we want to answer.
So yeah, that’s basically the class I’m teaching today and without talking about how to find W or any of that, it’s really just a = W*X which is pretty easy to understand from that regard if we don’t get into the math of finding W. Thankfully we have software to do it for us these days so it’s super straightforward to set it and forget it. But understanding how it works, why it works, and the limitations are all very important.
For example, amplitude is not conserved! Which is important to know, for example say we know what the source amplitude is because we’re infinitely powerful (bwahahahaha!!!) even if we separate our sources we don’t get to know the true amplitude (waah!). But everything is scaled so we don’t really need that information unless we’re doing something very specific with amplitude specifically. Frequency information is conserved.
Anyway that’s a basic rundown and maybe I’ll go into EVEN MORE detail later. But for now, I need to prep!



But enough about us, what about you?