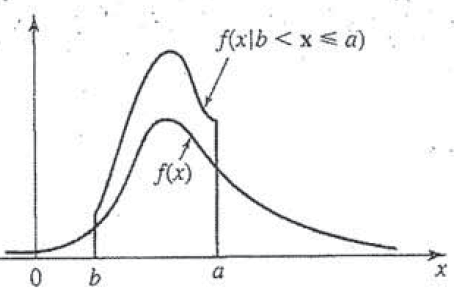
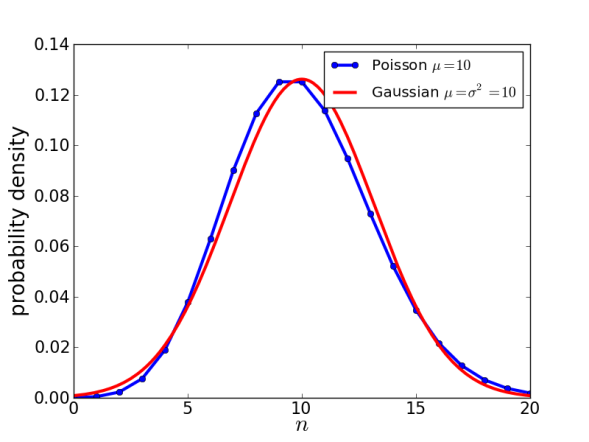
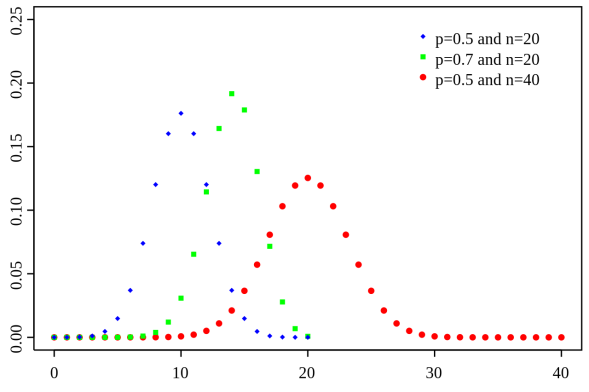
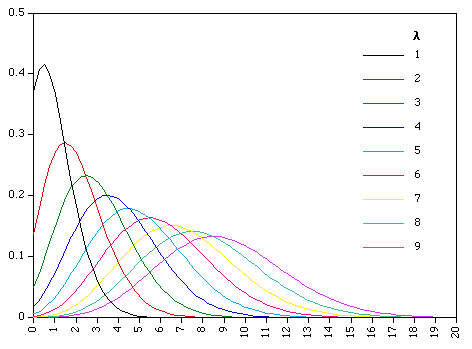
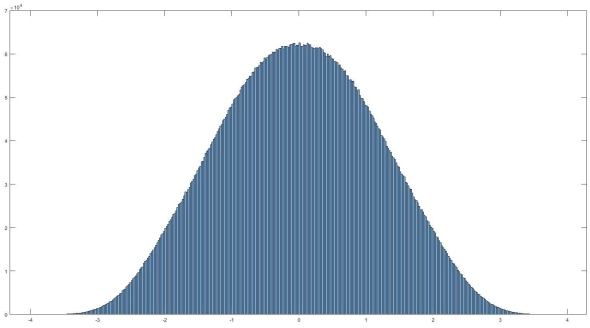
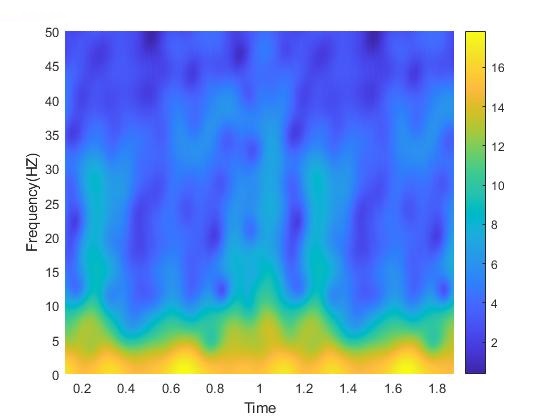
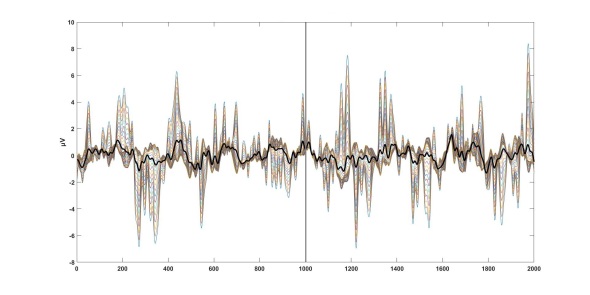
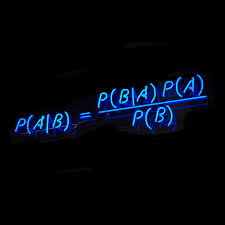Z-score bar graph that I made just for all of you using some data I had laying around. If you’re new to statistics it may not make sense, but rest assured we will make sense of it all!
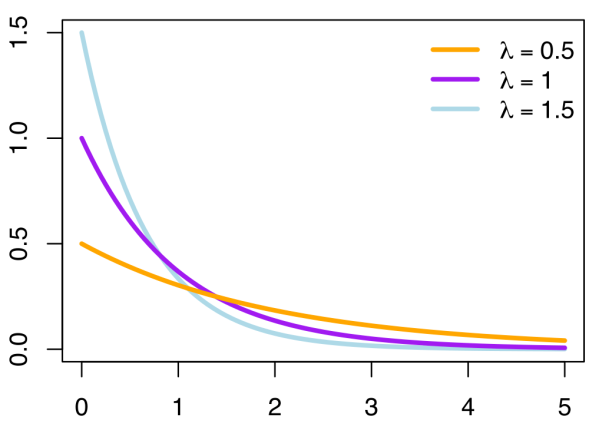
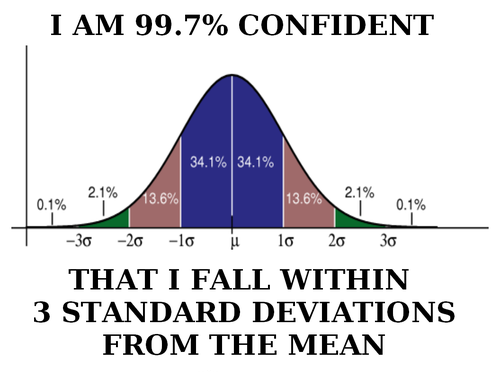
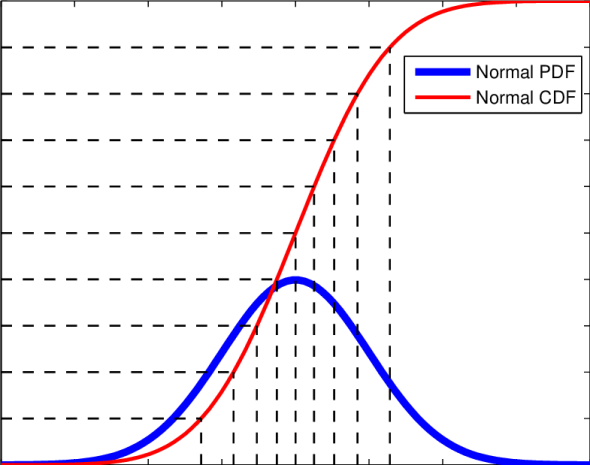
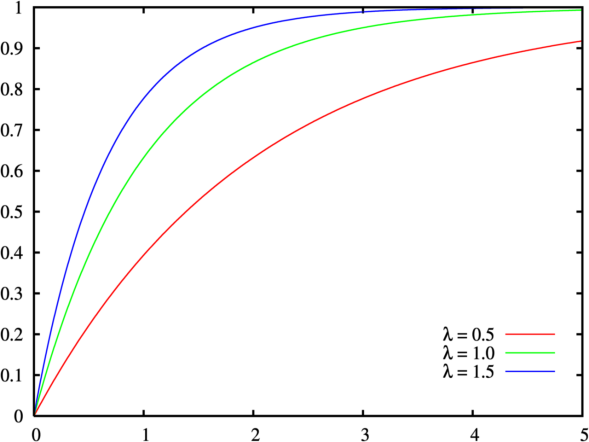
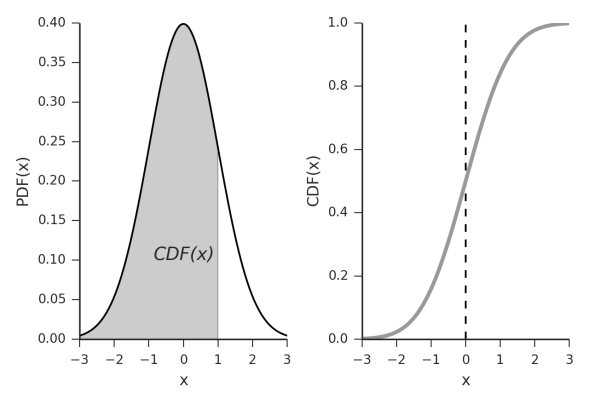
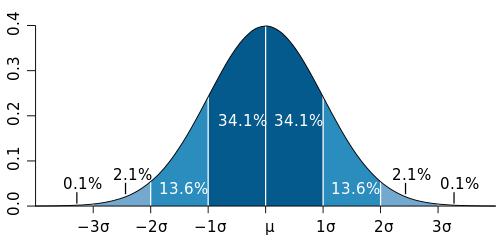
Well here we are two weeks into 365DoA, I was excited until I realized that puts us at 3.8356% of the way done. So if you remember from last post we’ve started our significance talk, as in what does it mean to have a value that is significant, what does that mean exactly, and how to do we find out? Today is the day I finally break, we’re going to have to do some math. Despite my best efforts I don’t think we can finish the significance discussion without it and still manage to make sense. With that, let’s just dive in.*
Read the rest of this page »
What happens in the lab doesn't have to stay in the lab!
Posted by The Lunatic |
September 2, 2019 | Categories: 365 Days of Academia - Year one | Tags: computer, Engineering, experiment, Math, matlab, neuroscience, null hypothesis, pascals triangle, probability, science, signal processing, statistics | Leave a comment